옵티마이저(Optimizer)는 사용자가 질의한 SQL문에 대해 최적의 실행 방법을 결정하는 역할을 수행한다.
이러한 최적의 실행 방법을 실행계획(Execution Plan)이라고 한다.
관계형 데이터베이스는 궁극적으로 SQL문을 통해서만 데이터를 처리할 수 있다.
JAVA, C등과 같은 프로그램 언어와는 달리 SQL은 사용자의 요구사항만 기술할 뿐 처리과정에 대한 기술은 하지 않는다. 그러므로 사용자의 요구사항을 만족하는 결과를 추출할 수 있는 다양한 실행 방법이 존재할 수 있다.
다양한 실행 방법들 중에서 최적의 실행 방법을 결정하는 것이 바로 옵티마이저의 역할이다.
관계형 데이터베이스는 옵티마이저가 결정한 실행 방법대로 실행 엔진이 데이터를 처리하여 결과 데이터를 사용자에게 전달할 뿐이다.
옵티마이저가 선택한 실행 방법의 적절성 여부는 질의의 수행 속도에 가장 큰 영향 미치게 된다.
이런 의미에서 관계형 데이터베이스에서 진정한 프로그래머는 옵티마이저라고 할 수 있다.
최적의 실행 방법 결정이라는 것은 어떤 방법으로 처리하는 것이 최소 일량으로 동일한 일을 처리할 수 있을지 결정하는 것이다.
그러나 이러한 결정을 옵티마이저는 실제로 SQL문을 처리해보지 않은 상태에서 결정해야 하는 어려움이 있다.
옵티마이저가 최적의 실행 방법을 결정하는 방식에 따라
규칙기반 옵티마이저(RBO, Rule Based Optimizer)와
비용기반 옵티마이저(CBO, Cost Based Optimizer)로 구분할 수 있다.
현재 대부분의 관계형 데이터베이스는 비용기반 옵티마이저만을 제공한다.
비록 규칙기반 옵티마이저를 제공하더라도 신규 기능들에 대해서는 더 이상 지원하지 않는다.
다만 하위 버전 호환성을 위해서만 규칙기반 옵티마이저가 남아 있을 뿐이다.
그렇지만 규칙기반 옵티마이저의 규칙은 보편 타당성에 근거한 것들이다.
이러한 규칙을 알고 있는 것은 옵티마이저의 최적화 작업을 이해하는데 도움이 된다.
가. 규칙기반 옵티마이저
규칙기반 옵티마이저는 규칙(우선 순위)을 가지고 실행계획을 생성한다.
실행계획을 생성하는 규칙을 이해하면 누구나 실행계획을 비교적 쉽게 예측할 수 있다.
규칙기반 옵티마이저가 실행계획을 생성할 때 참조하는 정보에는
가. SQL문을 실행하기 위해서 이용 가능한 인덱스 유무
나. 인덱스종류 (유일, 비유일, 단일, 복합 인덱스)
다. SQL문에서 사용하는 연산자의 종류(=, <, <>, LIKE, BETWEEN 등)
라. SQL문에서 참조하는 객체의 종류 (힙 테이블, 클러스터 테이블 등)
등이 있다.
이러한 정보에 따라 우선 순위(규칙)가 정해져 있고, 이 우선 순위를 기반으로 실행계획을 생성한다.
결과적으로 규칙기반 옵티마이저는 우선 순위가 높은 규칙이 적은 일량으로 해당 작업을 수행하는 방법이라고 판단하는 것이다.
Oracle의 규칙기반 옵티마이저의 15가지 규칙이다. 순위의 숫자가 낮을수록 높은 우선 순위이다.
규칙기반 옵티마이저의 우선 순위 규칙 중에서 주요한 규칙에 대해서만 간략히 설명한다.
규칙 1. Single row by rowid : ROWID를 통해서 테이블에서 하나의 행을 액세스하는 방식이다. ROWID는 행이 포함된 데이터 파일, 블록 등의 정보를 가지고 있기 때문에 다른 정보를 참조하지 않고도 바로 원하는 행을 액세스할 수 있다. 하나의 행을 액세스하는 가장 빠른 방법이다.
규칙 4. Single row by unique or primary key : 유일 인덱스(Unique Index)를 통해서 하나의 행을 액세스하는 방식이다. 이 방식은 인덱스를 먼저 액세스하고 인덱스에 존재하는 ROWID를 추출하여 테이블의 행을 액세스한다.
규칙 8. Composite index : 복합 인덱스에 동등(‘=’ 연산자) 조건으로 검색하는 경우이다.
예를 들어, 만약 A+B 칼럼으로 복합 인덱스가 생성되어 있고, 조건절에서 WHERE A=10 AND B=1 형태로 검색하는 방식이다. 복합 인덱스 사이의 우선 순위 규칙은 다음과 같다.
인덱스 구성 칼럼의 개수가 더 많고 해당 인덱스의 모든 구성 칼럼에 대해 ‘=’로 값이 주어질 수록 우선순위가 더 높다. 예를 들어, A+B로 구성된 인덱스와 A+B+C로 구성된 인덱스가 각각 존재하고 조건절에서 A, B, C 칼럼 모두에 대해 ‘=’로 값이 주어진다면 A+B+C 인덱스가 우선 순위가 높다.
만약 조건절에서 A, B 칼럼에만 ‘=’로 값이 주어진다면 A+B는 인덱스의 모든 구성 칼럼에 대해 값이 주어지고 A+B+C 인덱스 입장에서는 인덱스의 일부 칼럼에 대해서만 값이 주어졌기 때문에 A+B 인덱스가 우선 순위가 높게 된다.
규칙 9. Single column index : 단일 칼럼 인덱스에 ‘=’ 조건으로 검색하는 경우이다.
만약 A 칼럼에 단일 칼럼 인덱스가 생성되어 있고, 조건절에서 A=10 형태로 검색하는 방식이다.
규칙 10. Bounded range search on indexed columns : 인덱스가 생성되어 있는 칼럼에 양쪽 범위를 한정하는 형태로 검색하는 방식이다. 이러한 연산자에는 BETWEEN, LIKE 등이 있다.
만약 A 칼럼에 인덱스가 생성되어 있고, A BETWEEN ‘10’ AND ‘20’ 또는 A LIKE '1%' 형태로 검색하는 방식이다.
규칙 11. Unbounded range search on indexed columns : 인덱스가 생성되어 있는 칼럼에 한쪽 범위만 한정하는 형태로 검색하는 방식이다. 이러한 연산자에는 >, >=, <, <= 등이 있다.
만약 A 칼럼에 인덱스가 생성되어 있고, A > '10' 또는 A < '20' 형태로 검색하는 방식이다.
규칙 15. Full table scan : 전체 테이블을 액세스하면서 조건절에 주어진 조건을 만족하는 행만을 결과로 추출한다.
규칙기반 옵티마이저는 인덱스를 이용한 액세스 방식이 전체 테이블 액세스 방식보다 우선 순위가 높다. 따라서 규칙기반 옵티마이저는 해당 SQL문에서 이용 가능한 인덱스가 존재한다면 전체 테이블 액세스 방식보다는 항상 인덱스를 사용하는 실행계획을 생성한다.
규칙기반 옵티마이저가 조인 순서를 결정할 때는 조인 칼럼 인덱스의 존재 유무가 중요한 판단의 기준이다.
조인 칼럼에 대한 인덱스가 양쪽 테이블에 모두 존재한다면 앞에서 설명한 규칙에 따라 우선 순위가 높은 테이블을 선행 테이블(Driving Table)로 선택한다.
한쪽 조인 칼럼에만 인덱스가 존재하는 경우에는 인덱스가 없는 테이블을 선행 테이블로 선택해서 조인을 수행한다.
조인 칼럼에 모두 인덱스가 존재하지 않으면 FROM 절의 뒤에 나열된 테이블을 선행 테이블로 선택한다.
만약 조인 테이블의 우선 순위가 동일하다면 FROM 절에 나열된 테이블의 역순으로 선행 테이블을 선택한다.
규칙기반 옵티마이저의 조인 기법의 선택은 다음과 같다.
양쪽 조인 칼럼에 모두 인덱스가 없는 경우에는 Sort Merge Join을 사용하고 둘 중하나라도 조인 칼럼에 인덱스가 존재한다면 일반적으로 NL Join을 사용한다.
다음 SQL문을 이용해서 규칙기반 옵티마이저의 최적화 과정을 알아보자.
SELECT ENAME
FROM EMP
WHERE JOB = 'SALESMAN' AND SAL BETWEEN 3000 AND 6000 INDEX --------------------------------- EMP_JOB : JOB EMP_SAL : SAL PK_EMP : EMPNO (UNIQUE)
조건절에서 JOB 칼럼의 조건은 ‘=’, SAL 칼럼의 조건은 ‘BETWEEN’으로 값이 주어졌고 각각의 칼럼에 단일 칼럼 인덱스가 존재한다.
우선 순위 규칙에 따라 JOB 조건은 규칙 9의 단일 칼럼 인덱스를 만족하고 SAL 조건은 규칙 10의 인덱스상의 양쪽 한정 검색을 만족한다.
따라서 우선 순위가 높은 EMP_JOB 인덱스를 이용해서 조건을 만족하는 행에 대해 EMP 테이블을 액세스하는 방식을 선택할 것이다.
나.비용기반 옵티마이저
규칙기반 옵티마이저는 조건절에서 ‘=’ 연산자와 'BETWEEN' 연산자가 사용되면 규칙에 따라 ‘=’ 칼럼의 인덱스를 사용하는 것이 보다 적은 일량 즉, 보다 적은 처리 범위로 작업을 할 것이라고 판단한다.
그러나 실제로는 ‘BETWEEN’ 칼럼을 사용한 인덱스가 보다 일량이 적을 수 있다.
단순한 몇 개의 규칙만으로 현실의 모든 사항을 정확히 예측할 수는 없다.
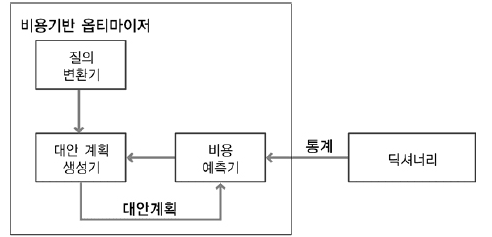
비용기반 옵티마이저는 이러한 규칙기반 옵티마이저의 단점을 극복하기 위해서 출현하였다.
비용기반 옵티마이저는 SQL문을 처리하는데 필요한 비용이 가장 적은 실행계획을 선택하는 방식이다.
여기서 비용이란 SQL문을 처리하기 위해 예상되는 소요시간 또는 자원 사용량을 의미한다.
비용기반 옵티마이저는 비용을 예측하기 위해서 규칙기반 옵티마이저가 사용하지 않는 테이블, 인덱스, 칼럼 등의 다양한 객체 통계정보와 시스템 통계정보 등을 이용한다.
통계정보가 없는 경우 비용기반 옵티마이저는 정확한 비용 예측이 불가능해져서 비효율적인 실행계획을 생성할 수 있다.
그렇기 때문에 정확한 통계정보를 유지하는 것은 비용기반 최적화에서 중요한 요소이다.
그림과 같이 비용기반 옵티마이저는 질의 변환기, 대안 계획 생성기, 비용 예측기 등의 모듈로 구성되어 있다.
질의 변환기는 사용자가 작성한 SQL문을 처리하기에 보다 용이한 형태로 변환하는 모듈이다.
대안 계획 생성기는 동일한 결과를 생성하는 다양한 대안 계획을 생성하는 모듈이다.
대안 계획은 연산의 적용 순서 변경, 연산 방법 변경, 조인 순서 변경 등을 통해서 생성된다.
동일한 결과를 생성하는 가능한 모든 대안 계획을 생성해야 보다 나은 최적화를 수행할 수 있다.
그러나 대안 계획의 생성이 너무 많아지면 최적화를 수행하는 시간이 그만큼 오래 걸린 수 있다.
그래서 대부분의 상용 옵티마이저들은 대안 계획의 수를 제약하는 다양한 방법을 사용한다.
이러한 현실적인 제약으로 인해 생성된 대안 계획들 중에서 최적의 대안 계획이 포함되지 않을 수도 있다.
비용 예측기는 대안 계획 생성기에 의해서 생성된 대안 계획의 비용을 예측하는 모듈이다.
대안 계획의 정확한 비용을 예측하기 위해서 연산의 중간 집합의 크기 및 결과 집합의 크기, 분포도 등의 예측이 정확해야 한다.
보다 나은 예측을 위해 옵티마이저는 정확한 통계정보를 필요로 한다.
또한 대안 계획을 구성하는 각 연산에 대한 비용 계산식이 정확해야 한다.
앞에서 규칙기반 옵티마이저는 항상 인덱스를 사용할 수 있다면 전체 테이블 스캔 보다는 인덱스를 사용하는 실행계획을 생성한다고 했다.
그렇지만 비용기반 옵티마이저는 인덱스를 사용하는 비용이 전체 테이블 스캔 비용보다 크다고 판단되면 전체 테이블 스캔을 수행하는 방법으로 실행계획을 생성할 수도 있다.
비용기반 옵티마이저는 통계정보, DBMS 버전, DBMS 설정 정보 등의 차이로 인해 동일 SQL문도 서로 다른 실행계획이 생성될 수 있다.
또한 비용기반 옵티마이저의 다양한 한계들로 인해 실행계획의 예측 및 제어가 어렵다는 단점이 있다.
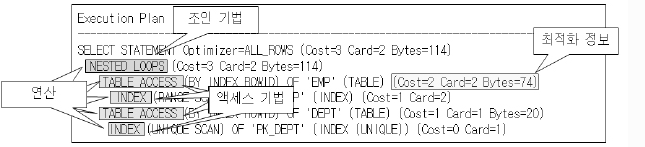
2) 실행계획
실행계획(Execution Plan)이란 SQL에서 요구한 사항을 처리하기 위한 절차와 방법을 의미한다.
실행계획을 생성한다는 것은 SQL을 어떤 순서로 어떻게 실행할 지를 결정하는 작업이다.
동일한 SQL에 대해 결과를 낼 수 있는 다양한 처리 방법(실행계획)이 존재할 수 있지만 각 처리 방법마다 실행 시간(성능)은 서로 다를 수 있다.
옵티마이저는 다양한 처리 방법들 중에서 가장 효율적인 방법을 찾아준다.
즉, 옵티마이저는 최적의 실행계획을 생성해 준다.
생성된 실행계획을 보는 방법은 데이터베이스 벤더마다 서로 다르다.
실행계획에서 표시되는 내용 및 형태도 약간씩 차이는 있지만 실행계획이 SQL 처리를 위한 절차와 방법을 의미한다는 기본적인 사항은 모두 동일하다.
실행계획을 보고 SQL이 어떻게 실행되는지 정확히 이해할 수 있다면 보다 향상된 SQL의 이해 및 활용이 가능하다.
실행계획을 구성하는 요소에는
가. 조인 순서(Join Order)
나. 조인 기법(Join Method)
다. 액세스 기법(Access Method)
라. 최적화 정보(Optimization Information)
마. 연산(Operation)
등이 있다.
조인 순서는 조인작업을 수행할 때 참조하는 테이블의 순서이다.
예를 들어, FROM 절에 A, B 두 개의 테이블이 존재할 때 조인 작업을 위해 먼저 A 테이블을 읽고 B 테이블을 읽는 작업을 수행한다면 조인 순서는 A → B이다.
논리적으로 가능한 조인 순서는 n! 만큼 존재한다. 여기서는 n은 FROM 절에 존재하는 테이블 수이다.
그러나 현실적으로 옵티마이저가 적용 가능한 조인 순서는 이보다는 적거나 같다.
조인 기법은 두 개의 테이블을 조인할 때 사용할 수 있는 방법으로서 여기에는 NL Join, Hash Join, Sort Merge Join 등이 있다.
액세스 기법은 하나의 테이블을 액세스할 때 사용할 수 있는 방법이다.
여기에는 인덱스를 이용하여 테이블을 액세스하는 인덱스 스캔(Index Scan)과 테이블 전체를 모두 읽으면서 조건을 만족하는 행을 찾는 전체 테이블 스캔(Full Table Scan) 등이 있다.
최적화 정보는 옵티마이저가 실행계획의 각 단계마다 예상되는 비용 사항을 표시한 것이다.
실행계획에 비용 사항이 표시된다는 것은 비용기반 최적화 방식으로 실행계획을 생성했다는 것을 의미한다.
최적화 정보에는 Cost, Card, Bytes가 있다.
Cost는 상대적인 비용 정보이고 Card는 Cardinality의 약자로서 주어진 조건을 만족한 결과 집합 혹은 조인 조건을 만족한 결과 집합의 건수를 의미한다. Bytes는 결과 집합이 차지하는 메모리 양을 바이트로 표시한 것이다.
이러한 비용 정보는 실제로 SQL을 실행하고 얻은 결과가 아니라 통계 정보를 바탕으로 옵티마이저가 계산한 예상치이다.
만약 이러한 비용 사항이 실행계획에 표시되지 않았다면 이것은 규칙기반 최적화 방식으로 실행계획을 생성한 것이다. 연산(Operation)은 여러 가지 조작을 통해서 원하는 결과를 얻어내는 일련의 작업이다.
연산에는 조인 기법(NL Join, Hash Join, Sort Merge Join 등), 액세스 기법(인덱스 스캔, 전체 테이블 스캔 등), 필터, 정렬, 집계, 뷰 등 다양한 종류가 존재한다.
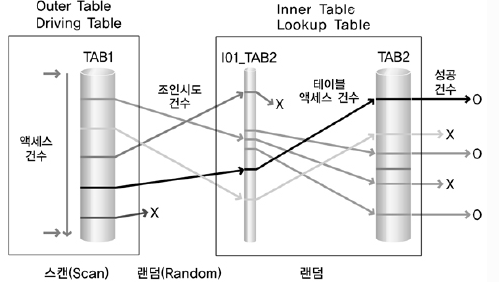
3) SQL 처리흐름도
SQL 처리 흐름도(Access Flow Diagram)란 SQL의 내부적인 처리 절차를 시각적으로 표현한 도표이다.
이것은 실행계획을 시각화한 것이다.
그림과 같이 액세스 처리 흐름도에는 SQL문의 처리를 위해 어떤 테이블을 먼저 읽었는지(조인 순서), 테이블을 읽기 위해서 인덱스 스캔을 수행했는지 또는 테이블 전체 스캔을 수행했는지(액세스 기법)과 조인 기법 등을 표현할 수 있다.
예를 들어,조인 순서는 TAB1 → TAB2이다.
여기서 TAB1을 Outer Table 또는 Driving Table이라고 하고, TAB2를 Inner Table 또는 Lookup Table이라고 한다.
테이블의 액세스 방법은 TAB1은 테이블 전체 스캔을 의미하고 TAB2는 I01_TAB2 이라는 인덱스를 통한 인덱스 스캔을 했음을 표시한 것이다.
조인 방법은 NL Join을 수행했음을 표시한 것이다.
그림에서 TAB1에 대한 액세스는 스캔(Scan) 방식이고 조인시도 및 I01_TAB2 인덱스를 통한 TAB2 액세스는 랜덤(Random) 방식이다.
대량의 데이터를 랜덤 방식으로 액세스하게 되면 많은 I/O가 발생하여 성능상 좋지 않다.
성능적인 관점을 살펴보기 위해서 SQL 처리 흐름도에 일량을 함께 표시할 수 있다.
그림에서 건수(액세스 건수, 조인 시도 건수, 테이블 액세스 건수, 성공 건수)라고 표시된 곳에 SQL 처리를 위해 작업한 건수 또는 처리 결과 건수 등의 일량을 함께 표시할 수 있다.
이것을 통해 어느 부분에서 비효율이 발생하고 있는지에 대한 힌트를 얻을 수 있다.
2. 인덱스 기본
1) 인덱스 특징과 종류
인덱스는 원하는 데이터를 쉽게 찾을 수 있도록 돕는 책갈피와 유사한 개념이다.
인덱스는 테이블을 기반으로 선택적으로 생성할 수 있는 구조이다.
테이블에 인덱스를 생성하지 않아도 되고 여러 개를 생성해도 된다.
인덱스의 기본적인 목적은 검색 성능의 최적화이다.
즉, 검색 조건을 만족하는 데이터를 인덱스를 통해 효과적으로 찾을 수 있도록 돕는다.
그렇지만 Insert, Update, Delete 등과 같은 DML 작업은 테이블과 인덱스를 함께 변경해야 하기 때문에 오히려 느려질 수 있다는 단점이 존재한다.
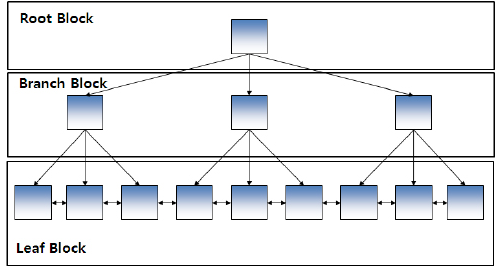
가. 트리 기반 인덱스
DBMS에서 가장 일반적인 인덱스는 B-트리 인덱스이다.
그림과 같이 B-트리 인덱스는 브랜치 블록(Branch Block)과 리프 블록(Leaf Block)으로 구성된다.
브랜치 블록 중에서 가장 상위에서 있는 블록을 루트 블록(Root Block)이라고 한다.
브랜치 블록은 분기를 목적으로 하는 블록이다.
브랜치 블록은 다음 단계의 블록을 가리키는 포인터를 가지고 있다.
리프 블록은 트리의 가장 아래 단계에 존재한다.
리프 블록은 인덱스를 구성하는 칼럼의 데이터와 해당 데이터를 가지고 있는 행의 위치를 가리키는 레코드 식별자(RID, Record Identifier/Rowid)로 구성되어 있다.
인덱스 데이터는 인덱스를 구성하는 칼럼의 값으로 정렬된다.
만약 인덱스 데이터의 값이 동일하면 레코드 식별자의 순서로 저장된다.
리프 블록은 양방향 링크(Double Link)를 가지고 있다.
이것을 통해서 오름 차순(Ascending Order)과 내림 차순(Descending Order) 검색을 쉽게 할 수 있다.
B-트리 인덱스는 ‘=’로 검색하는 일치(Exact Match) 검색과 ‘BETWEEN’, ‘>’ 등과 같은 연산자로 검색하는 범위(Range) 검색 모두에 적합한 구조이다.
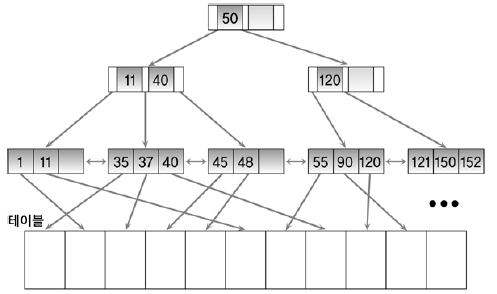
그림은 브랜치 브록이 3개의 포인터로 구성된 B-트리 인덱스의 예이다.
인덱스에서 원하는 값을 찾는 과정은 다음과 같다.
1단계. 브랜치 블록의 가장 왼쪽 값이 찾고자 하는 값보다 작거나 같으면 왼쪽 포인터로 이동
2단계. 찾고자 하는 값이 브랜치 블록의 값 사이에 존재하면 가운데 포인터로 이동
3단계. 오른쪽에 있는 값보다 크면 오른쪽 포인터로 이동
이 과정을 리프 블록을 찾을 때까지 반복한다. 리프 블록에서 찾고자 하는 값이 존재하면 해당 값을 찾은 것이고, 해당 값이 없으면 해당 값은 존재하지 않아 검색에 실패하게 된다.
예를 들어, 그림에서 37을 찾고자 한다면 루트 블록에서 50보다 작으므로 왼쪽 포인터로 이동한다.
37는 왼쪽 브랜치 블록의 11과 40 사이의 값이므로 가운데 포인터로 이동한다.
이동한 결과 해당 블록이 리프 블록이므로 37이 블록 내에 존재하는지 검색한다.
본 예에서는 리프 블록에 37이 존재한다. 검색하고자 하는 값을 찾은 것이다.
만약, SQL문에서 다른 칼럼이 더 필요하면 리프 블록에 존재하는 레코드 식별자를 이용해서 테이블을 액세스한다.
만약, 37과 50사이의 모든 값을 찾고자 한다면(BETWEEN 37 AND 50) 위와 동일한 방법으로 리프 블록에서 37을 찾고 50보다 큰 값을 만날 때까지 오른쪽으로 이동하면서 인덱스를 읽는다.
이것은 인덱스 데이터가 정렬되어 있고 리프 블록이 양방향 링크로 연결되어 있기 때문에 가능하다.
인덱스를 경유해서 반환된 결과 데이터는 인덱스 데이터와 동일한 순서로 갖게 되는 특징을 갖는다.
인덱스를 생성할 때 동일 칼럼으로 구성된 인덱스를 중복해서 생성할 수 없다.
그렇지만 인덱스 구성 칼럼은 동일하지만 칼럼의 순서가 다르면 서로 다른 인덱스로 생성할 수 있다.
예를 들어, JOB+SAL 칼럼 순서의 인덱스와 SAL+JOB 칼럼 순서의 인덱스를 별도의 인덱스를 생성할 수 있다.
인덱스의 칼럼 순서는 질의의 성능에 중요한 영향을 미치는 요소이다.
Oracle에서 트리 기반 인덱스에는 B-트리 인덱스 외에도 비트맵 인덱스(Bitmap Index), 리버스 키 인덱스(Reverse Key Index), 함수기반 인덱스(FBI, Function-Based Index) 등이 존재한다.
나. SQL Server의 클러스터형 인덱스
SQL Server의 인덱스 종류
저장 구조에 따라
클러스터형(clustered) 인덱스
비클러스터형(nonclustered) 인덱스
여기서는 클러스터형 인덱스에 대해서만 설명하기로 한다.
클러스터형 인덱스는 두 가지 중요한 특징이 있다.
첫째, 인덱스의 리프 페이지가 곧 데이터 페이지다.
따라서 테이블 탐색에 필요한 레코드 식별자가 리프 페이지에 없다(인덱스 키 칼럼과 나머지 칼럼을 리프 페이지에 같이 저장하기 때문에 테이블을 랜덤 액세스할 필요가 없다).
클러스터형 인덱스의 리프 페이지를 탐색하면 해당 테이블의 모든 칼럼 값을 곧바로 얻을 수 있다.
흔히 클러스터형 인덱스를 사전에 비유한다.
예를 들어, 영한사전은 알파벳 순으로 정렬되어 있으며 각 단어 바로 옆에 한글 설명이 붙어 있다.
전문서적 끝 부분에 있는 찾아보기(=색인)가 페이지 번호만 알려주는 것과 비교하면 그 차이점을 알 수 있다.
둘째, 리프 페이지의 모든 로우(=데이터)는 인덱스 키 칼럼 순으로 물리적으로 정렬되어 저장된다.
테이블 로우는 물리적으로 한 가지 순서로만 정렬될 수 있다.
그러므로 클러스터형 인덱스는 테이블당 한 개만 생성할 수 있다.(전화번호부 한 권을 상호와 인명으로 동시에 정렬할 수 없는 것과 마찬가지다.)
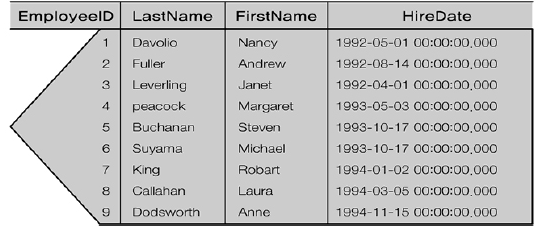
그림은 Employee ID, Last Name, First Name, Hire Date로 구성된 Employees 테이블에 대해 Employee ID에 기반한 클러스터형 인덱스를 생성한 모습이다. B-트리 구조를 편의상, 삼각형 모양을 왼쪽으로 90도 돌려서 나타냈다.
리프 블록에 인덱스 키 칼럼 외에도 테이블의 나머지 칼럼이 모두 함께 있다.
2) 전체 테이블 스캔과 인덱스 스캔
가. 전체 테이블 스캔
전체 테이블 스캔 방식으로 데이터를 검색한다는 것은 테이블에 존재하는 모든 데이터를 읽어 가면서 조건에 맞으면 결과로서 추출하고 조건에 맞지 않으면 버리는 방식으로 검색한다.
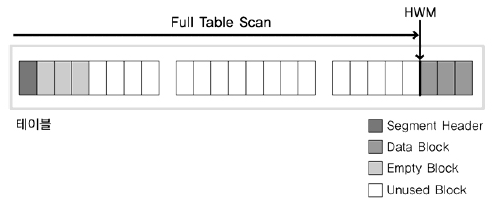
Oracle의 경우 그림과 같이 검색 조건에 맞는 데이터를 찾기 위해서 테이블의 고수위 마크(HWM, High Water Mark) 아래의 모든 블록을 읽는다.
고수위 마크는 테이블에 데이터가 쓰여졌던 블록 상의 최상위 위치(현재는 지워져서 데이터가 존재하지 않을 수도 있음)를 의미한다.
전체 테이블 스캔 방식으로 데이터를 검색할 때 고수기 때문에 모든 결과를 찾을 때까지 시간이 오래 걸릴 수 있다.
이와 같이 전체 테이블 스캔 방식은 테이블에 존재하는 모든 블록의 데이터를 읽는다.
그러나 이것은 결과를 찾기 위해 꼭 필요해서 모든 블록을 읽은 것이다.
따라서 이렇게 읽은 블록들은 재사용성이 떨어진다.
그래서 전체 테이블 스캔 방식으로 읽은 블록들은 메모리에서 곧 제거될 수 있도록 관리된다.
옵티마이저가 연산으로서 전체 테이블 스캔 방식을 선택하는 이유는 일반적으로 다음과 같다.
1) SQL문에 조건이 존재하지 않는 경우
SQL문에 조건이 존재하지 않는다는 것은 테이블에 존재하는 모든 데이터가 답이 된다는 것이다.
그렇기 때문에 테이블의 모든 블록을 읽으면서 무조건 결과로서 반환하면 된다.
2) SQL문의 주어진 조건에 사용 가능한 인덱스가 존재하는 않는 경우
사용 가능한 인덱스가 존재하지 않는다면 데이터를 액세스할 수 있는 방법은 테이블의 모든 데이터를 읽으면서 주어진 조건을 만족하는지를 검사하는 방법뿐이다.
또한 주어진 조건에 사용 가능한 인덱스는 존재하나 함수를 사용하여 인덱스 칼럼을 변형한 경우에도 인덱스를 사용할 수 없다.
3) 옵티마이저의 취사 선택
조건을 만족하는 데이터가 많은 경우, 결과를 추출하기 위해서 테이블의 대부분의 블록을 액세스해야 한다고 옵티마이저가 판단하면 조건에 사용 가능한 인덱스가 존재해도 전체 테이블 스캔 방식으로 읽을 수 있다.
4) 그 밖의 경우
병렬처리 방식으로 처리하는 경우 또는 전체 테이블 스캔 방식의 힌트를 사용한 경우에 전체 테이블 스캔 방식으로 데이터를 읽을 수 있다.
나. 인덱스 스캔
여기서는 데이터베이스에서 주로 사용되는 트리 기반 인덱스를 중심으로 설명한다.
인덱스 스캔은 인덱스를 구성하는 칼럼의 값을 기반으로 데이터를 추출하는 액세스 기법이다.
인덱스의 리프 블록은 인덱스 구성하는 칼럼과 레코드 식별자로 구성되어 있다.
따라서 검색을 위해 인덱스의 리프 블록을 읽으면 인덱스 구성 칼럼의 값과 테이블의 레코드 식별자를 알 수 있다.
인덱스에 존재하지 않는 칼럼의 값이 필요한 경우에는 현재 읽은 레코드 식별자를 이용하여 테이블을 액세스해야 한다. 그러나 SQL문에서 필요로 하는 모든 칼럼이 인덱스 구성 칼럼에 포함된 경우 테이블에 대한 액세스는 발생하지 않는다. 인덱스는 인덱스 구성 칼럼의 순서로 정렬되어 있다.
인덱스의 구성 칼럼이 A+B라면 먼저 칼럼 A로 정렬되고 칼럼 A의 값이 동일할 경우에는 칼럼 B로 정렬된다.
그리고 칼럼 B까지 모두 동일하면 레코드 식별자로 정렬된다.
인덱스가 구성 칼럼으로 정렬되어 있기 때문에 인덱스를 경유하여 데이터를 읽으면 그 결과 또한 정렬되어 반환된다.
따라서 인덱스의 순서와 동일한 정렬 순서를 사용자가 원하는 경우에는 정렬 작업을 하지 않을 수 있다.
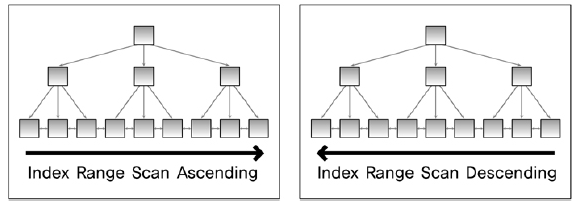
인덱스 스캔 중에서 자주 사용되는 인덱스 유일 스캔(Index Unique Scan),
인덱스 범위 스캔(Index Range Scan),
인덱스 역순 범위 스캔(Index Range Scan Descending)에 대해 간단히 설명하면 다음과 같다.
제공되는 인덱스 스캔 방식은 데이터베이스 벤더마다 다를 수 있다.
1) 인덱스 유일 스캔은 유일 인덱스(Unique Index)를 사용하여 단 하나의 데이터를 추출하는 방식이다.
유일 인덱스는 중복을 허락하지 않는 인덱스이다.
유일 인덱스 구성 칼럼에 모두 '='로 값이 주어지면 결과는 최대 1건이 된다.
인덱스 유일 스캔은 유일 인덱스 구성 칼럼에 대해 모두 ‘=’로 값이 주어진 경우에만 가능한 인덱스 스캔 방식이다.
2) 인덱스 범위 스캔은 인덱스를 이용하여 한 건 이상의 데이터를 추출하는 방식이다.
유일 인덱스의 구성 칼럼 모두에 대해 ‘=’로 값이 주어지지 않은 경우와 비유일 인덱스(Non-Unique Index)를 이용하는 모든 액세스 방식은 인덱스 범위 스캔 방식으로 데이터를 액세스하는 것이다.
왼쪽 그림과 같은 방식으로 인덱스를 읽는다.
3) 인덱스 역순 범위 스캔은 그림의 오른쪽 그림과 같이 인덱스의 리프 블록의 양방향 링크를 이용하여 내림 차순으로 데이터를 읽는 방식이다. 이 방식을 이용하여 최대값(Max Value)을 쉽게 찾을 수 있다. 이 또한 인덱스 범위 스캔의 일종이다.
이외에도 인덱스 전체 스캔(Index Full Scan), 인덱스 고속 전체 스캔(Fast Full Index Scan), 인덱스 스킵 스캔(Index Skip Scan) 등이 존재한다.
다. 규칙기반 옵티마이저
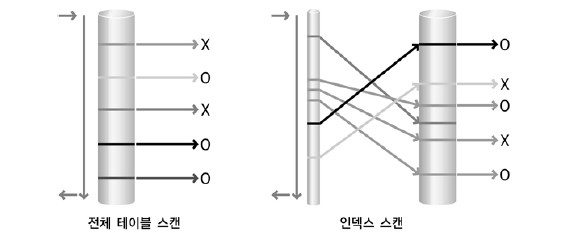
데이터를 액세스하는 방법은 크게 두 가지로 나눠 볼 수 있다. 인덱스를 경유해서 읽는 인덱스 스캔 방식과 테이블의 전체 데이터를 모두 읽으면서 데이터를 추출하는 전체 테이블 스캔 방식이다. 인덱스 스캔 방식은 사용 가능한 적절한 인덱스가 존재할 때만 이용할 수 있는 스캔 방식이지만 전체 테이블 스캔 방식은 인덱스의 존재 유무와 상관없이 항상 이용 가능한 스캔 방식이다. 앞에서 설명한 것처럼 옵티마이저는 인덱스가 존재하더라도 전체 테이블 스캔 방식을 취사 선택할 수 있다. [그림 Ⅱ-3-11]은 전체 테이블 스캔과 인덱스 스캔에 대한 SQL 처리 흐름도 표현의 예이다.
3. 조인 수행 원리
1) NL JOIN
조인이란 두 개 이상의 테이블을 하나의 집합으로 만드는 연산이다.
SQL문에서 FROM 절에 두 개 이상의 테이블이 나열될 경우 조인이 수행된다.
조인 연산은 두 테이블 사이에서 수행된다.
FROM 절에 A, B, C라는 세 개의 테이블이 존재하더라도 세 개의 테이블이 동시에 조인이 수행되는 것은 아니다.
세 개의 테이블 중에서 먼저 두 개의 테이블에 대해 조인이 수행된다.
그리고 먼저 수행된 조인 결과와 나머지 테이블 사이에서 조인이 수행된다.
테이블 또는 조인 결과를 이용하여 조인을 수행할 때 조인 단계별로 다른 조인 기법을 사용할 수 있다.
예를 들어, A와 B 테이블을 조인할 때는 NL Join 기법을 사용하고 해당 조인 결과와 C 테이블을 조인할 때는 Hash Join 기법을 사용할 수 있다.
조인 기법은 두 개의 테이블을 조인할 때 사용할 수 있는 방법이다.
여기서는 조인 기법 중에서 자주 사용되는 NL Join, Hash Join, Sort Merge Join에 대해서 조인 원리를 간단하게 설명한다.
NL Join은 프로그래밍에서 사용하는 중첩된 반복문과 유사한 방식으로 조인을 수행한다.
반복문의 외부에 있는 테이블을 선행 테이블 또는 외부 테이블(Outer Table)이라고 하고, 반복문의 내부에 있는 테이블을 후행 테이블 또는 내부 테이블(Inner Table)이라고 한다.
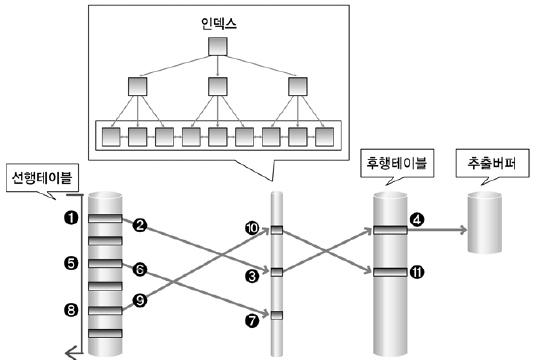
FOR 선행 테이블 읽음 → 외부 테이블(Outer Table) FOR 후행 테이블 읽음 → 내부 테이블(Inner Table) (선행 테이블과 후행 테이블 조인)
먼저 선행 테이블의 조건을 만족하는 행을 추출하여 후행 테이블을 읽으면서 조인을 수행한다.
이 작업은 선행 테이블의 조건을 만족하는 모든 행의 수만큼 반복 수행한다.
NL Join에서는 선행 테이블의 조건을 만족하는 행의 수가 많으면(처리 주관 범위가 넓으면), 그 만큼 후행 테이블의 조인 작업은 반복 수행된다.
따라서 결과 행의 수가 적은(처리 주관 범위가 좁은) 테이블을 조인 순서상 선행 테이블로 선택하는 것이 전체 일량을 줄일 수 있다.
NL Join은 랜덤 방식으로 데이터를 액세스하기 때문에 처리 범위가 좁은 것이 유리하다.
NL Join의 작업 방법은 다음과 같다.
① 선행 테이블에서 주어진 조건을 만족하는 행을 찾음
② 선행 테이블의 조인 키 값을 가지고 후행 테이블에서 조인 수행
③ 선행 테이블의 조건을 만족하는 모든 행에 대해 1번 작업 반복 수행
① 선행 테이블에서 조건을 만족하는 첫 번째 행을 찾음 → 이때 선행 테이블에 주어진 조건을 만족하지 않는 경우 해당 데이터는 필터링 됨
② 선행 테이블의 조인 키를 가지고 후행 테이블에 조인 키가 존재하는지 찾으러 감 → 조인 시도
③ 후행 테이블의 인덱스에 선행 테이블의 조인 키가 존재하는지 확인 → 선행 테이블의 조인 값이 후행 테이블에 존재하지 않으면 선행 테이블 데이터는 필터링 됨 (더 이상 조인 작업을 진행할 필요 없음)
④ 인덱스에서 추출한 레코드 식별자를 이용하여 후행 테이블을 액세스 → 인덱스 스캔을 통한 테이블 액세스 후행 테이블에 주어진 조건까지 모두 만족하면 해당 행을 추출버퍼에 넣음
⑤ ~ ⑪ 앞의 작업을 반복 수행함
추출버퍼는 SQL문의 실행결과를 보관하는 버퍼로서 일정 크기를 설정하여 추출버퍼에 결과가 모두 차거나 더 이상 결과가 없어서 추출버퍼를 채울 것이 없으면 결과를 사용자에게 반환한다.
추출버퍼는 운반단위, Array Size, Prefetch Size라고도 한다.
그림에서 만약 선행 테이블에 사용 가능한 인덱스가 존재한다면 인덱스를 통해 선행 테이블을 액세스할 수 있다. (여기서는 사용할 인덱스가 없음을 가정으로 설명한 것임)
NL Join 기법은 조인이 성공하면 바로 조인 결과를 사용자에게 보여 줄 수 있다.
그래서 결과를 가능한 빨리 화면에 보여줘야 하는 온라인 프로그램에 적당한 조인 기법이다.
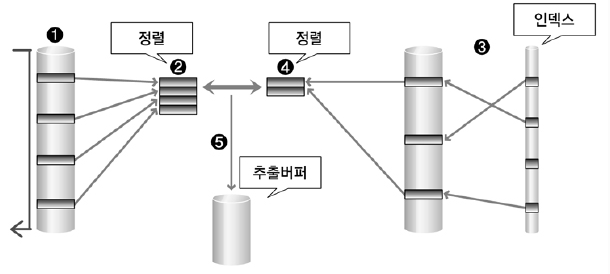
2) Sort Merge Join
Sort Merge Join은 조인 칼럼을 기준으로 데이터를 정렬하여 조인을 수행한다.
NL Join은 주로 랜덤 액세스 방식으로 데이터를 읽는 반면 Sort Merge Join은 주로 스캔 방식으로 데이터를 읽는다.
Sort Merge Join은 랜덤 액세스로 NL Join에서 부담이 되던 넓은 범위의 데이터를 처리할 때 이용되던 조인 기법이다. 그러나 Sort Merge Join은 정렬할 데이터가 많아 메모리에서 모든 정렬 작업을 수행하기 어려운 경우에는 임시 영역(디스크)을 사용하기 때문에 성능이 떨어질 수 있다.
일반적으로 대량의 조인 작업에서 정렬 작업을 필요로 하는 Sort Merge Join 보다는 CPU 작업 위주로 처리하는 Hash Join이 성능상 유리하다.
그러나 Sort Merge Join은 Hash Join과는 달리 동등 조인 뿐만 아니라 비동등 조인에 대해서도 조인 작업이 가능하다는 장점이 있다.
① 선행 테이블에서 주어진 조건을 만족하는 행을 찾음
② 선행 테이블의 조인 키를 기준으로 정렬 작업을 수행
① ~ ②번 작업을 선행 테이블의 조건을 만족하는 모든 행에 대해 반복 수행
③ 후행 테이블에서 주어진 조건을 만족하는 행을 찾음
④ 후행 테이블의 조인 키를 기준으로 정렬 작업을 수행
③ ~ ④번 작업을 후행 테이블의 조건을 만족하는 모든 행에 대해 반복 수행
⑤ 정렬된 결과를 이용하여 조인을 수행하며 조인에 성공하면 추출버퍼에 넣음
Sort Merge Join은 조인 칼럼의 인덱스를 사용하지 않기 때문에 조인 칼럼의 인덱스가 존재하지 않을 경우에도 사용할 수 있는 조인 기법이다.
Sort Merge Join에서 조인 작업을 위해 항상 정렬 작업이 발생하는 것은 아니다.
예를 들어, 조인할 테이블 중에서 이미 앞 단계의 작업을 수행하는 도중에 정렬 작업이 미리 수행되었다면 조인을 위한 정렬 작업은 발생하지 않을 수 있다.
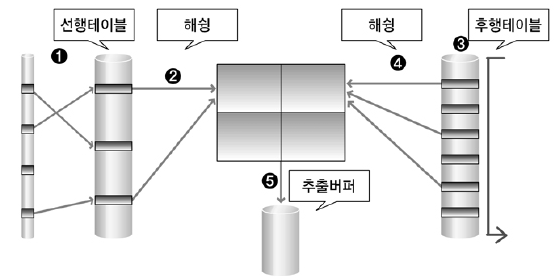
3) Hash Join
Hash Join은 해쉬 기법을 이용하여 조인을 수행한다.
조인을 수행할 테이블의 조인 칼럼을 기준으로 해쉬 함수를 수행하여 서로 동일한 해쉬 값을 갖는 것들 사이에서 실제 값이 같은지를 비교하면서 조인을 수행한다.
Hash Join은 NL Join의 랜덤 액세스 문제점과 Sort Merge Join의 문제점인 정렬 작업의 부담을 해결 위한 대안으로 등장하였다.
① 선행 테이블에서 주어진 조건을 만족하는 행을 찾음
② 선행 테이블의 조인 키를 기준으로 해쉬 함수를 적용하여 해쉬 테이블을 생성 → 조인 칼럼과 SELECT 절에서 필요로 하는 칼럼도 함께 저장됨
① ~ ②번 작업을 선행 테이블의 조건을 만족하는 모든 행에 대해 반복 수행
③ 후행 테이블에서 주어진 조건을 만족하는 행을 찾음
④ 후행 테이블의 조인 키를 기준으로 해쉬 함수를 적용하여 해당 버킷을 찾음 → 조인 키를 이용해서 실제 조인될 데이터를 찾음
⑤ 조인에 성공하면 추출버퍼에 넣음 ③ ~ ⑤번 작업을 후행 테이블의 조건을 만족하는 모든 행에 대해서 반복 수행
Hash Join은 조인 칼럼의 인덱스를 사용하지 않기 때문에 조인 칼럼의 인덱스가 존재하지 않을 경우에도 사용할 수 있는 조인 기법이다.
Hash Join은 해쉬 함수를 이용하여 조인을 수행하기 때문에 '='로 수행하는 조인 즉, 동등 조인에서만 사용할 수 있다.
해쉬 함수를 적용한 값은 어떤 값으로 해슁될 지 알 수 없다.
해쉬 함수가 적용될 때 동일한 값은 항상 같은 값으로 해슁됨이 보장된다.
그러나 해쉬 함수를 적용할 때 보다 큰 값이 항상 큰 값으로 해슁되고 작은 값이 항상 작은 값으로 해슁된다는 보장은 없다.
그렇기 때문에 Hash Join은 동등 조인에서만 사용할 수 있다.
그림과 같이 Hash Join은 조인 작업을 수행하기 위해 해쉬 테이블을 메모리에 생성해야 한다.
생성된 해쉬 테이블의 크기가 메모리에 적재할 수 있는 크기보다 더 커지면 임시 영역(디스크)에 해쉬 테이블을 저장한다.
그러면 추가적인 작업이 필요해 진다.
그렇기 때문에 Hash Join을 할 때는 결과 행의 수가 적은 테이블을 선행 테이블로 사용하는 것이 좋다.
Hash Join에서는 선행 테이블을 이용하여 먼저 해쉬 테이블을 생성한다고 해서 선행 테이블을 Build Input이라고도 하며, 후행 테이블은 만들어진 해쉬 테이블에 대해 해쉬 값의 존재여부를 검사한다고 해서 Prove Input이라고도 한다.
내장 함수는 벤더별로 가장 큰 차이를 보이는 부분이지만, 핵심적인 기능들은 이름이나 표현법이 다르더라도 대부분의 데이터베이스가 공통적으로 제공하고 있다.
내장 함수는 다시 함수의 입력 값이 단일행 값이 입력되는 단일행 함수(Single-Row Function)
여러 행의 값이 입력되는 다중행 함수(Multi-Row Function)로 나눌 수 있다.
다중행 함수는 다시 집계 함수(Aggregate Function),
그룹 함수(Group Function),
윈도우 함수(Window Function)로 나눌 수 있다.
함수는 입력되는 값이 아무리 많아도 출력은 하나만 된다는 M:1 관계라는 중요한 특징을 가지고 있다.
단일행 함수의 경우 단일행 내에 있는 하나의 값 또는 여러 값이 입력 인수로 표현될 수 있다.
다중행 함수의 경우도 여러 레코드의 값들을 입력 인수로 사용하는 것이다.
함수명 (칼럼이나 표현식 [, Arg1, Arg2, ... ])
단일행 함수의 중요한 특징
가. SELECT, WHERE, ORDER BY 절에 사용 가능하다.
나. 각 행(Row)들에 대해 개별적으로 작용하여 데이터 값들을 조작하고, 각각의 행에 대한 조작 결과를 리턴한다.
다. 여러 인자(Argument)를 입력해도 단 하나의 결과만 리턴한다.
라. 함수의 인자(Arguments)로 상수, 변수, 표현식이 사용 가능하고, 하나의 인수를 가지는 경우도 있지만 여러 개의 인수를 가질 수도 있다.
마. 특별한 경우가 아니면 함수의 인자(Arguments)로 함수를 사용하는 함수의 중첩이 가능하다.
2) 문자형 함수
문자형 함수는 문자 데이터를 매개 변수로 받아들여서 문자나 숫자 값의 결과를 돌려주는 함수이다. 몇몇 문자형 함수의 경우는 결과를 숫자로 리턴하는 함수도 있다.
[예제] ‘SQL Expert’라는 문자형 데이터의 길이를 구하는 문자형 함수를 사용한다.
[답안] Oracle SELECT LENGTH('SQL Expert') FROM DUAL; LENGTH('SQL Expert')
--------------- 10
예제 및 실행 결과를 보면 함수에 대한 결과 값을 마치 테이블에서 값을 조회했을 때와 비슷하게 표현한다.
Oracle은 SELECT 절과 FROM 절 두 개의 절을 SELECT 문장의 필수 절로 지정하였으므로 사용자 테이블이 필요 없는 SQL 문장의 경우에도 필수적으로 DUAL이라는 테이블을 FROM 절에 지정한다.
DUAL 테이블의 특성은 다음과 같다.
가. 사용자 SYS가 소유하며 모든 사용자가 액세스 가능한 테이블이다.
나. SELECT ~ FROM ~ 의 형식을 갖추기 위한 일종의 DUMMY 테이블이다.
다. DUMMY라는 문자열 유형의 칼럼에 'X'라는 값이 들어 있는 행을 1건 포함하고 있다.
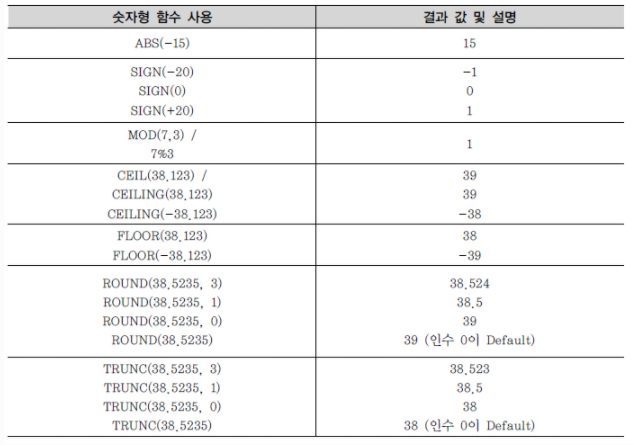
3) 숫자형 함수
숫자형 함수는 숫자 데이터를 입력받아 처리하고 숫자를 리턴하는 함수이다.
4) 날짜형 함수
날짜형 함수는 DATE 타입의 값을 연산하는 함수이다.
Oracle의 TO_NUMBER(TO_CHAR( )) 함수의 경우 변환형 함수로 구분할 수도 있으나 SQL Server의 YEAR, MONTH,DAY 함수와 매핑하기 위하여 날짜형 함수에서 설명한다.
EXTRACT/DATEPART는 같은 기능을 하는 Oracle 내장 함수와 SQL Server 내장 함수를 표현한 것이다.
DATE 변수가 데이터베이스에 어떻게 저장되는지 살펴보면, 데이터베이스는 날짜를 저장할 때 내부적으로 세기(Century), 년(Year), 월(Month), 일(Day), 시(Hours), 분(Minutes), 초(Seconds)와 같은 숫자 형식으로 변환하여 저장한다. 날짜는 여러 가지 형식으로 출력이 되고 날짜 계산에도 사용되기 때문에 그 편리성을 위해서 숫자형으로 저장하는 것이다.
데이터베이스는 날짜를 숫자로 저장하기 때문에 덧셈, 뺄셈 같은 산술 연산자로도 계산이 가능하다.
즉, 날짜에 숫자 상수를 더하거나 뺄 수 있다.
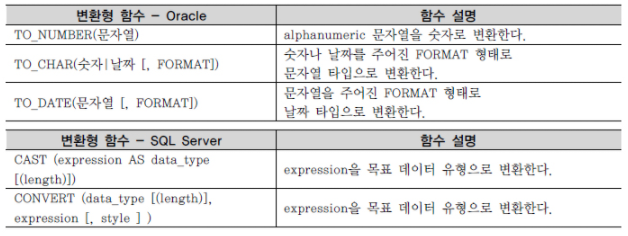
5) 변환형 함수
변환형 함수는 특정 데이터 타입을 다양한 형식으로 출력하고 싶을 경우에 사용되는 함수이다.
변환형 함수는 크게 두 가지 방식이 있다.
암시적 데이터 유형 변환의 경우 성능 저하가 발생할 수 있으며, 자동적으로 데이터베이스가 알아서 계산하지 않는 경우가 있어 에러를 발생할 수 있으므로 명시적인 데이터 유형 변환 방법을 사용하는 것이 바람직하다.
명시적 데이터 유형 변환에 사용되는 대표적인 변환형 함수는 다음과 같다.
변환형 함수를 사용하여 출력 형식을 지정할 때, 숫자형과 날짜형의 경우 상당히 많은 포맷이 벤더별로 제공된다.
벤더별 데이터 유형과 함께 데이터 출력의 포맷 부분은 벤더의 고유 항목이 많으므로 매뉴얼을 참고하기 바라며, 아래는 대표적인 사례 몇 가지만 소개한다.
[결과] SELECT TO_CHAR(123456789/1200,'$999,999,999.99') 환율반영달러, TO_CHAR(123456789,'L999,999,999') 원화 FROM DUAL;
[출력]환율반영달러 원화 $102,880.66 \123,456,789
두 번째 칼럼의 L999에서 L은 로칼 화폐 단위를 의미한다.
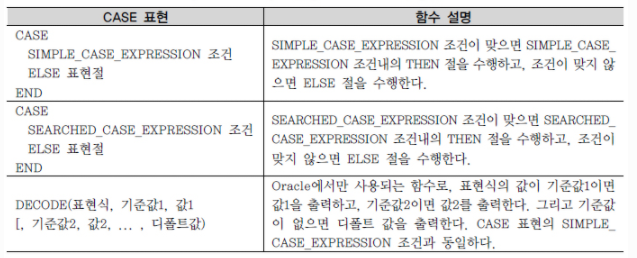
6) CASE 표현
CASE 표현은 IF-THEN-ELSE 논리와 유사한 방식으로 표현식을 작성해서 SQL의 비교 연산 기능을 보완하는 역할을 한다. ANSI/ISO SQL 표준에는 CASE Expression이라고 표시되어 있는데, 함수와 같은 성격을 가지고 있으며 Oracle의 Decode 함수와 같은 기능을 하므로 단일행 내장 함수에서 같이 설명을 한다.
CASE 표현을 하기 위해서는 조건절을 표현하는 두 가지 방법이 있고, Oracle의 경우 DECODE 함수를 사용할 수도 있다.
IF-THEN-ELSE 논리를 구현하는 CASE Expressions은 Simple Case Expression과 Searched Case Expression 두 가지 표현법 중에 하나를 선택해서 사용하게 된다.
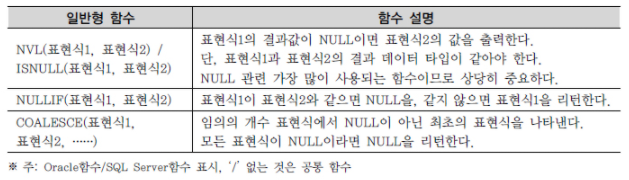
7) NULL 관련 함수
NULL에 대한 특성
가. 널 값은 아직 정의되지 않은 값으로 0 또는 공백과 다르다. 0은 숫자이고, 공백은 하나의 문자이다.
나. 테이블을 생성할 때 NOT NULL 또는 PRIMARY KEY로 정의되지 않은 모든 데이터 유형은 널 값을 포함할 수 있다.
다. 널 값을 포함하는 연산의 경우 결과 값도 널 값이다. 모르는 데이터에 숫자를 더하거나 빼도 결과는 마찬가지로 모르는 데이터인 것과 같다.
라. 결과값을 NULL이 아닌 다른 값을 얻고자 할 때 NVL/ISNULL 함수를 사용한다.
NULL 값의 대상이 숫자 유형 데이터인 경우는 주로 0(Zero)으로, 문자 유형 데이터인 경우는 블랭크보다는 ‘x’ 같이 해당 시스템에서 의미 없는 문자로 바꾸는 경우가 많다.
가. NVL / ISNULL 함수
2. GROUP BY, HAVING 절
1) 집계 함수(Aggregate Function)
집계 함수는 여러 행들의 그룹이 모여서 그룹당 단 하나의 결과를 돌려주는 다중행 함수이다.
집계 함수(Aggregate Function)의 특성.
가. 여러 행들의 그룹이 모여서 그룹당 단 하나의 결과를 돌려주는 함수이다.
나. GROUP BY 절은 행들을 소그룹화 한다.
다. SELECT 절, HAVING 절, ORDER BY 절에 사용할 수 있다.
집계 함수명 ( [DISTINCT | ALL] 칼럼이나 표현식 ) - ALL : Default 옵션이므로 생략 가능함 - DISTINCT : 같은 값을 하나의 데이터로 간주할 때 사용하는 옵션임
집계 함수는 그룹에 대한 정보를 제공하므로 주로 숫자 유형에 사용되지만, MAX, MIN, COUNT 함수는 문자, 날짜 유형에도 적용이 가능한 함수이다.
2) GROUP BY 절
WHERE 절을 통해 조건에 맞는 데이터를 조회했지만 테이블에 1차적으로 존재하는 데이터 이외의 정보,
예를 들면 각 팀별로 선수가 몇 명인지,
선수들의 평균 신장과 몸무게가 얼마나 되는지,
또는 각 팀에서 가장 큰 키의 선수가 누구인지 등의 2차 가공 정보도 필요하다.
GROUP BY 절은 SQL 문에서 FROM 절과 WHERE 절 뒤에 오며, 데이터들을 작은 그룹으로 분류하여 소그룹에 대한 항목별로 통계 정보를 얻을 때 추가로 사용된다.
SELECT [DISTINCT] 칼럼명 [ALIAS명] FROM 테이블명 [WHERE 조건식] [GROUP BY 칼럼(Column)이나 표현식] [HAVING 그룹조건식] ;
GROUP BY 절과 HAVING 절은 다음과 같은 특성을 가진다.
가. GROUP BY 절을 통해 소그룹별 기준을 정한 후, SELECT 절에 집계 함수를 사용한다.
나. 집계 함수의 통계 정보는 NULL 값을 가진 행을 제외하고 수행한다.
다. GROUP BY 절에서는 SELECT 절과는 달리 ALIAS 명을 사용할 수 없다.
라. 집계 함수는 WHERE 절에는 올 수 없다. (집계 함수를 사용할 수 있는 GROUP BY 절보다 WHERE 절이 먼저 수행된다)
마. WHERE 절은 전체 데이터를 GROUP으로 나누기 전에 행들을 미리 제거시킨다.
바. HAVING 절은 GROUP BY 절의 기준 항목이나 소그룹의 집계 함수를 이용한 조건을 표시할 수 있다.
사. GROUP BY 절에 의한 소그룹별로 만들어진 집계 데이터 중, HAVING 절에서 제한 조건을 두어 조건을 만족하는 내용만 출력한다.
아. HAVING 절은 일반적으로 GROUP BY 절 뒤에 위치한다.
3) HAVING 절
WHERE 절에는 집계 함수는 사용할 수 없다.
WHERE 절은 FROM 절에 정의된 집합(주로 테이블)의 개별 행에 WHERE 절의 조건절이 먼저 적용되고,
WHERE 절의 조건에 맞는 행이 GROUP BY 절의 대상이 된다.
그런 다음 결과 집합의 행에 HAVING 조건절이 적용된다.
결과적으로 HAVING 절의 조건을 만족하는 내용만 출력된다.
즉, HAVING 절은 WHERE 절과 비슷하지만 그룹을 나타내는 결과 집합의 행에 조건이 적용된다는 점에서 차이가 있다.
GROUP BY 소그룹의 데이터 중 일부만 필요한 경우,
GROUP BY 연산 전 WHERE 절에서 조건을 적용하여 필요한 데이터만 추출하여 GROUP BY 연산을 하는 방법과,
GROUP BY 연산 후 HAVING 절에서 필요한 데이터만 필터링 하는 두 가지 방법을 사용할 수 있다.
같은 실행 결과를 얻는 두 가지 방법 중 HAVING 절에서 TEAM_ID 같은 GROUP BY 기준 칼럼에 대한 조건을 추가할 수도 있으나,
가능하면 WHERE 절에서 조건절을 적용하여 GROUP BY의 계산 대상을 줄이는 것이 효율적인 자원 사용 측면에서 바람직하다.
4) 집계 함수와 NULL
리포트의 빈칸을 NULL이 아닌 ZERO로 표현하기 위해 NVL(Oracle)/ISNULL(SQL Server) 함수를 사용하는 경우가 많은데, 다중 행 함수를 사용하는 경우는 오히려 불필요한 부하가 발생하므로 굳이 NVL 함수를 다중 행 함수 안에 사용할 필요가 없다.
다중 행 함수는 입력 값으로 전체 건수가 NULL 값인 경우만 함수의 결과가 NULL이 나오고 전체 건수 중에서 일부만 NULL인 경우는 NULL인 행을 다중 행 함수의 대상에서 제외한다.
예를 들면 100명 중 10명의 성적이 NULL 값일 때 평균을 구하는 다중 행 함수 AVG를 사용하면 NULL 값이 아닌 90명의 성적에 대해서 평균값을 구하게 된다.
CASE 표현 사용시 ELSE 절을 생략하게 되면 Default 값이 NULL이다.
NULL은 연산의 대상이 아닌 반면, SUM(CASE MONTH WHEN 1 THEN SAL ELSE 0 END)처럼 ELSE 절에서 0(Zero)을 지정하면 불필요하게 0이 SUM 연산에 사용되므로 자원의 사용이 많아진다.
같은 결과를 얻을 수 있다면 가능한 ELSE 절의 상수값을 지정하지 않거나 ELSE 절을 작성하지 않도록 한다.
같은 이유로 Oracle의 DECODE 함수는 4번째 인자를 지정하지 않으면 NULL이 Default로 할당된다.
많이 실수하는 것 중에 하나가 Oracle의 SUM(NVL(SAL,0)), SQL Server의 SUM(ISNULL (SAL,0)) 연산이다.
개별 데이터의 급여(SAL)가 NULL인 경우는 NULL의 특성으로 자동적으로 SUM 연산에서 빠지는 데, 불필요하게 NVL/ISNULL 함수를 사용해 0(Zero)으로 변환시켜 데이터 건수만큼의 연산이 일어나게 하는 것은 시스템의 자원을 낭비하는 일이다.
리포트 출력 때 NULL이 아닌 0을 표시하고 싶은 경우에는 NVL(SUM(SAL),0)이나, ISNULL(SUM(SAL),0)처럼 전체 SUM의 결과가 NULL인 경우(대상 건수가 모두 NULL인 경우)에만 한 번 NVL/ISNULL 함수를 사용하면 된다.
3. ORDER BY 절
1) ORDER BY 정렬
ORDER BY 절은 SQL 문장으로 조회된 데이터들을 다양한 목적에 맞게 특정 칼럼을 기준으로 정렬하여 출력하는데 사용한다.
ORDER BY 절에 칼럼(Column)명 대신에 SELECT 절에서 사용한 ALIAS 명이나 칼럼 순서를 나타내는 정수도 사용 가능하다.
기본적으로 오름차순이 적용되며, SQL 문장의 제일 마지막에 위치한다.
SELECT 칼럼명 [ALIAS명] FROM 테이블명 [WHERE 조건식] [GROUP BY 칼럼(Column)이나 표현식] [HAVING 그룹조건식] [ORDER BY 칼럼(Column)이나 표현식 [ASC 또는 DESC]] ; ASC(Ascending) : 조회한 데이터를 오름차순으로 정렬한다.(기본 값이므로 생략 가능) DESC(Descending) : 조회한 데이터를 내림차순으로 정렬한다.
ORDER BY 특징
가. 기본적인 정렬 순서는 오름차순(ASC)이다.
나. 숫자형 데이터 타입은 오름차순으로 정렬했을 경우에 가장 작은 값부터 출력된다.
다. 날짜형 데이터 타입은 오름차순으로 정렬했을 경우 날짜 값이 가장 빠른 값이 먼저 출력된다.
예를 들어 ‘01-JAN-2012’는 ‘01-SEP-2012’보다 먼저 출력된다.
다. Oracle에서는 NULL 값을 가장 큰 값으로 간주하여 오름차순으로 정렬했을 경우에는 가장 마지막에, 내림차순으로 정렬했을 경우에는 가장 먼저 위치한다.
라. 반면, SQL Server에서는 NULL 값을 가장 작은 값으로 간주하여 오름차순으로 정렬했을 경우에는 가장 먼저, 내림차순으로 정렬했을 경우에는 가장 마지막에 위치한다.
2) SELECT 문장 실행순서
GROUP BY 절과 ORDER BY가 같이 사용될 때 SELECT 문장은 6개의 절로 구성이 되고,
SELECT 문장의 수행 단계는 아래와 같다.
5. SELECT 칼럼명 [ALIAS명]
1. FROM 테이블명
2. WHERE 조건식
3. GROUP BY 칼럼(Column)이나 표현식
4. HAVING 그룹조건식
6. ORDER BY 칼럼(Column)이나 표현식;
1. 발췌 대상 테이블을 참조한다. (FROM)
2. 발췌 대상 데이터가 아닌 것은 제거한다. (WHERE)
3. 행들을 소그룹화 한다. (GROUP BY)
4. 그룹핑된 값의 조건에 맞는 것만을 출력한다. (HAVING)
5. 데이터 값을 출력/계산한다. (SELECT)
6. 데이터를 정렬한다. (ORDER BY)
위 순서는 옵티마이저가 SQL 문장의 SYNTAX, SEMANTIC 에러를 점검하는 순서이기도 하다.
예를 들면 FROM 절에 정의되지 않은 테이블의 칼럼을 WHERE 절, GROUP BY 절, HAVING 절, SELECT 절, ORDER BY 절에서 사용하면 에러가 발생한다.
그러나 ORDER BY 절에는 SELECT 목록에 나타나지 않은 문자형 항목이 포함될 수 있다.
단, SELECT DISTINCT를 지정하거나 SQL 문장에 GROUP BY 절이 있거나 또는 SELECT 문에 UNION 연산자가 있으면 열 정의가 SELECT 목록에 표시되어야 한다.
이 부분은 관계형 데이터베이스가 데이터를 메모리에 올릴 때 행 단위로 모든 칼럼을 가져오게 되므로, SELECT 절에서 일부 칼럼만 선택하더라도 ORDER BY 절에서 메모리에 올라와 있는 다른 칼럼의 데이터를 사용할 수 있다.
그러나 서브쿼리의 SELECT 절에서 선택되지 않은 칼럼들은 계속 유지되는 것이 아니라 서브쿼리 범위를 벗어나면 더 이상 사용할 수 없게 된다. (인라인 뷰도 동일함)
GROUP BY 절에서 그룹핑 기준을 정의하게 되면 데이터베이스는 일반적인 SELECT 문장처럼 FROM 절에 정의된 테이블의 구조를 그대로 가지고 가는 것이 아니라, GROUP BY 절의 그룹핑 기준에 사용된 칼럼과 집계 함수에 사용될 수 있는 숫자형 데이터 칼럼들의 집합을 새로 만든다.
GROUP BY 절을 사용하게 되면 그룹핑 기준에 사용된 칼럼과 집계 함수에 사용될 수 있는 숫자형 데이터 칼럼들의 집합을 새로 만드는데, 개별 데이터는 필요 없으므로 저장하지 않는다.
GROUP BY 이후 수행 절인 SELECT 절이나 ORDER BY 절에서 개별 데이터를 사용하는 경우 에러가 발생한다.
결과적으로 SELECT 절에서는 그룹핑 기준과 숫자 형식 칼럼의 집계 함수를 사용할 수 있지만, 그룹핑 기준 외의 문자 형식 칼럼은 정할 수 없다.
4. 조인 ( JOIN )
1) JOIN 개요
지금까지는 하나의 테이블에서 데이터를 출력하는 것을 살펴보았다. 하지만, 이것은 일상생활에서 발생하는 다양한 조건을 만족하는 SQL 문장을 작성하기에는 부족하다.
두 개 이상의 테이블과 연결 또는 결합하여 데이터를 출력하는 경우가 아주 많이 발생한다.
두 개 이상의 테이블 들을 연결 또는 결합하여 데이터를 출력하는 것을 JOIN이라고 하며, 일반적으로 사용되는 SQL 문장의 상당수가 JOIN이라고 생각하면 JOIN의 중요성을 이해하기 쉬울 것이다.
JOIN은 관계형 데이터베이스의 가장 큰 장점이면서 대표적인 핵심 기능이라고 할 수 있다.
일반적인 경우 행들은 PRIMARY KEY(PK)나 FOREIGN KEY(FK) 값의 연관에 의해 JOIN이 성립된다.
하지만 어떤 경우에는 이러한 PK, FK의 관계가 없어도 논리적인 값들의 연관만으로 JOIN이 성립 가능하다.
한 가지 주의할 점은 FROM 절에 여러 테이블이 나열되더라도 SQL에서 데이터를 처리할 때는 단 두 개의 집합 간에만 조인이 일어난다는 것이다.
FROM 절에 A, B, C 테이블이 나열되었더라도 특정 2개의 테이블만 먼저 조인 처리되고, 2개의 테이블이 조인되어서 처리된 새로운 데이터 집합과 남은 한 개의 테이블이 다음 차례로 조인되는 것이다. 이순서는 4개 이상의 테이블이 사용되더라도 같은 프로세스를 반복한다.
예를 들어 A, B, C, D 4개의 테이블을 조인하고자 할 경우 옵티마이저는 ( ( (A JOIN D) JOIN C) JOIN B)와 같이 순차적으로 조인을 처리하게 된다.
2) EQUI JOIN
EQUI(등가) JOIN은 두 개의 테이블 간에 칼럼 값들이 서로 정확하게 일치하는 경우에 사용되는 방법으로
대부분 PK ↔ FK의 관계를 기반으로 한다.
그러나 일반적으로 테이블 설계 시에 나타난 PK ↔ FK의 관계를 이용하는 것이지 반드시 PK ↔ FK의 관계로만 EQUI JOIN이 성립하는 것은 아니다.
이 기능은 관계형 데이터베이스의 큰 장점이다.
JOIN의 조건은 WHERE 절에 기술하게 되는데 “=” 연산자를 사용해서 표현한다.
다음은 EQUI JOIN의 대략적인 형태이다.
SELECT 테이블1.칼럼명, 테이블2.칼럼명, ... FROM 테이블1, 테이블2 WHERE 테이블1.칼럼명1 = 테이블2.칼럼명2; → WHERE 절에 JOIN 조건을 넣는다.
위 SQL을 보면 SELECT 구문에 단순히 칼럼명이 오지 않고 “테이블명.칼럼명”처럼 테이블명과 칼럼명이 같이 나타난다. 이렇게 특정 칼럼에 접근하기 위해 그 칼럼이 어느 테이블에 존재하는 칼럼인지를 명시하는 것은 두 가지 이유가 있다.
첫 번째는 모든 테이블에 칼럼들이 유일한 이름을 가진다면 상관없지만,
JOIN에 사용되는 두 개의 테이블에 같은 칼럼명이 존재하는 경우에는 DBMS의 옵티마이저는 어떤 칼럼을 사용해야 할지 모르기 때문에 파싱 단계에서 에러가 발생된다.
두 번째는 개발자나 사용자가 조회할 데이터가 어느 테이블에 있는 칼럼을 말하는 것인지 쉽게 알 수 있게 하므로 SQL에 대한 가독성이나 유지보수성을 높이는 효과가 있다.
하나의 SQL 문장 내에서 유일하게 사용하는 칼럼명이라면 칼럼명 앞에 테이블 명을 붙이지 않아도 되지만, 현재 두 집합에서 유일하다고 하여 미래에도 두 집합에서 유일하다는 보장은 없기 때문에 향후 발생할 오류를 방지하고 일관성을 위해 유일한 칼럼도 출력할 칼럼명 앞에 테이블명을 붙여서 사용하는 습관을 기르는 것을 권장한다.
조인 조건에 맞는 데이터만 출력하는 INNER JOIN에 참여하는 대상 테이블이 N개라고 했을 때, N개의 테이블로부터 필요한 데이터를 조회하기 위해 필요한 JOIN 조건은 대상 테이블의 개수에서 하나를 뺀 N-1개 이상이 필요하다.
즉 FROM 절에 테이블이 3개가 표시되어 있다면 JOIN 조건은 3-1=2개 이상이 필요하며, 테이블이 4개가 표시되어 있다면 JOIN 조건은 4-1=3개 이상이 필요하다. (옵티마이저의 발전으로 옵티마이저가 일부 JOIN 조건을 실행계획 수립 단계에서 추가할 수도 있지만, 예외적인 사항이다.)
3) Non EQUI JOIN
Non EQUI(비등가) JOIN은 두 개의 테이블 간에 칼럼 값들이 서로 정확하게 일치하지 않는 경우에 사용된다.
Non EQUI JOIN의 경우에는 “=” 연산자가 아닌 다른(Between, >, >=, <, <= 등) 연산자들을 사용하여 JOIN을 수행하는 것이다.
두 개의 테이블이 PK-FK로 연관관계를 가지거나 논리적으로 같은 값이 존재하는 경우에는 “=” 연산자를 이용하여 EQUI JOIN을 사용한다.
그러나 두 개의 테이블 간에 칼럼 값들이 서로 정확하게 일치하지 않는 경우에는 EQUI JOIN을 사용할 수 없다.
이런 경우 Non EQUI JOIN을 시도할 수 있으나 데이터 모델에 따라서 Non EQUI JOIN이 불가능한 경우도 있다.
다음은 Non EQUI JOIN의 대략적인 형태이다.
아래 BETWEEN a AND b 조건은 Non EQUI JOIN의 한 사례일 뿐이다.
SELECT 테이블1.칼럼명, 테이블2.칼럼명, ... FROM 테이블1, 테이블2 WHERE 테이블1.칼럼명1 BETWEEN 테이블2.칼럼명1 AND 테이블2.칼럼명2;
4) JOIN 을 하는 이유
지금까지 JOIN에 대한 기본적인 사용법을 확인해 보았는데, JOIN이 필요한 기본적인 이유는 과목1에서 배운 정규화에서부터 출발한다.
정규화란 불필요한 데이터의 정합성을 확보하고 이상현상(Anomaly) 발생을 피하기 위해,
테이블을 분할하여 생성하는 것이다.
사실 데이터웨어하우스 모델처럼 하나의 테이블에 모든 데이터를 집중시켜놓고 그 테이블로부터 필요한 데이터를 조회할 수도 있다.
그러나 이렇게 됐을 경우, 가장 중요한 데이터의 정합성에 더 큰 비용을 지불해야 하며, 데이터를 추가, 삭제, 수정하는 작업 역시 상당한 노력이 요구될 것이다.
성능 측면에서도 간단한 데이터를 조회하는 경우에도 규모가 큰 테이블에서 필요한 데이터를 찾아야 하기 때문에 오히려 검색 속도가 떨어질 수도 있다.
테이블을 정규화하여 데이터를 분할하게 되면 위와 같은 문제는 자연스럽게 해결 된다.
그렇지만 특정 요구조건을 만족하는 데이터들을 분할된 테이블로부터 조회하기 위해서는 테이블 간에 논리적인 연관관계가 필요하고 그런 관계성을 통해서 다양한 데이터들을 출력할 수 있는 것이다.
그리고, 이런 논리적인 관계를 구체적으로 표현하는 것이 바로 SQL 문장의 JOIN 조건인 것이다.
관계형 데이터베이스의 큰 장점이면서, SQL 튜닝의 중요 대상이 되는 JOIN을 잘못 기술하게 되면 시스템 자원 부족이나 과다한 응답시간 지연을 발생시키는 중요 원인이 되므로 JOIN 조건은 신중하게 작성해야 한다.
1. TCL ( Transaction Control Language : 트랜잭션 제어어 )
1) 트랜잭션 개요
트랜잭션은 데이터베이스의 논리적 연산단위이다.
트랜잭션(TRANSACTION)이란 밀접히 관련되어 분리될 수 없는 한 개 이상의 데이터베이스 조작을 가리킨다.
하나의 트랜잭션에는 하나 이상의 SQL 문장이 포함된다.
트랜잭션은 분할할 수 없는 최소의 단위이다.
그렇기 때문에 전부 적용하거나 전부 취소한다.
즉, TRANSACTION은 ALL OR NOTHING의 개념인 것이다.
은행에서의 계좌이체 상황을 연상하면 트랜잭션을 이해하는데 도움이 된다.
계좌이체는 최소한 두 가지 이상의 작업으로 이루어져 있다.
우선 자신의 계좌에서 잔액을 확인하고 이체할 금액을 인출한 다음 나머지 금액을 저장한다.
그리고 이체할 계좌를 확인하고 앞에서 인출한 금액을 더한 다음에 저장하면 계좌이체가 성공한다.
계좌이체 사례
가. 100번 계좌의 잔액에서 10,000원을 뺀다.
나. 200번 계좌의 잔액에 10,000원을 더한다.
계좌이체라는 작업 단위는 이런 두 개의 업데이트가 모두 성공적으로 완료되었을 때 종료된다.
둘 중 하나라도 실패할 경우 계좌이체는 원래의 금액을 유지하고 있어야만 한다.
만약 어떠한 장애에 의해 어느 쪽이든 한 쪽만 실행했을 경우, 이체한 금액은 어디로 증발해 버렸거나 마음대로 증가하게 된다.
당연히 그런 일이 있어서는 안 되므로 이러한 경우에는 수정을 취소하여 원 상태로 되돌려야 한다.
이런 계좌이체 같은 하나의 논리적인 작업 단위를 구성하는 세부적인 연산들의 집합을 트랜잭션이라 한다.
이런 관점에서 데이터베이스 응용 프로그램은 트랜잭션의 집합으로 정의할 수도 있다.
올바르게 반영된 데이터를 데이터베이스에 반영시키는 것을 커밋(COMMIT), 트랜잭션 시작 이전의 상태로 되돌리는 것을 롤백(ROLLBACK)이라고 하며, 저장점(SAVEPOINT) 기능과 함께 3가지 명령어를 트랜잭션을 콘트롤하는 TCL(TRANSACTION CONTROL LANGUAGE)로 분류한다.
트랜잭션의 대상이 되는 SQL문은 UPDATE, INSERT, DELETE 등 데이터를 수정하는 DML 문이다.
트랜잭션의 특성
2) COMMIT
입력한 자료나 수정한 자료에 대해서 또는 삭제한 자료에 대해서 전혀 문제가 없다고 판단되었을 경우 COMMIT 명령어를 통해서 트랜잭션을 완료할 수 있다.
COMMIT이나 ROLLBACK 이전의 데이터 상태는 다음과 같다.
가. 단지 메모리 BUFFER에만 영향을 받았기 때문에 데이터의 변경 이전 상태로 복구 가능하다.
나. 현재 사용자는 SELECT 문장으로 결과를 확인 가능하다.
다. 다른 사용자는 현재 사용자가 수행한 명령의 결과를 볼 수 없다.
라. 변경된 행은 잠금(LOCKING)이 설정되어서 다른 사용자가 변경할 수 없다.
COMMIT 이후의 데이터 상태는 다음과 같다.
가. 데이터에 대한 변경 사항이 데이터베이스에 반영된다.
나. 이전 데이터는 영원히 잃어버리게 된다.
다. 모든 사용자는 결과를 볼 수 있다.
라. 관련된 행에 대한 잠금(LOCKING)이 풀리고, 다른 사용자들이 행을 조작할 수 있게 된다.
Oracle은 DML을 실행하는 경우 DBMS가 트랜잭션을 내부적으로 실행하며,
DML 문장 수행 후 사용자가 임의로 COMMIT 혹은 ROLLBACK을 수행해 주어야 트랜잭션이 종료된다.
(일부 툴에서는 AUTO COMMIT을 옵션으로 선택할 수 있다.)
하지만, SQL Server는 기본적으로 AUTO COMMIT 모드이기 때문에 DML 수행 후 사용자가 COMMIT이나 ROLLBACK을 처리할 필요가 없다.
DML 구문이 성공이면 자동으로 COMMIT이 되고 오류가 발생할 경우 자동으로 ROLLBACK 처리된다.
3) ROLLBACK
테이블 내 입력한 데이터나, 수정한 데이터, 삭제한 데이터에 대하여 COMMIT 이전에는 변경 사항을 취소할 수 있는데 데이터베이스에서는 롤백(ROLLBACK) 기능을 사용한다.
롤백(ROLLBACK)은 데이터 변경 사항이 취소되어 데이터의 이전 상태로 복구되며, 관련된 행에 대한 잠금(LOCKING)이 풀리고 다른 사용자들이 데이터 변경을 할 수 있게 된다.
ROLLBACK 후의 데이터 상태는 다음과 같다.
가. 데이터에 대한 변경 사항은 취소된다.
나. 이전 데이터는 다시 재저장된다.
다. 관련된 행에 대한 잠금(LOCKING)이 풀리고, 다른 사용자들이 행을 조작할 수 있게 된다.
COMMIT과 ROLLBACK을 사용함으로써 다음과 같은 효과를 볼 수 있다.
가. 데이터 무결성 보장
나. 영구적인 변경을 하기 전에 데이터의 변경 사항 확인 가능
다. 논리적으로 연관된 작업을 그룹핑하여 처리 가능
4) SAVEPOINT
저장점(SAVEPOINT)을 정의하면 롤백(ROLLBACK)할 때 트랜잭션에 포함된 전체 작업을 롤백하는 것이 아니라 현 시점에서 SAVEPOINT까지 트랜잭션의 일부만 롤백할 수 있다.
따라서 복잡한 대규모 트랜잭션에서 에러가 발생했을 때 SAVEPOINT까지의 트랜잭션만 롤백하고 실패한 부분에 대해서만 다시 실행할 수 있다. (일부 툴에서는 지원이 안 될 수 있음)
복수의 저장점을 정의할 수 있으며, 동일이름으로 저장점을 정의했을 때는 나중에 정의한 저장점이 유효하다.
다음의 SQL문은 SVPT1이라는 저장점을 정의하고 있다.
SAVEPOINT SVPT1;
저장점까지 롤백할 때는 ROLLBACK 뒤에 저장점 명을 지정한다.
ROLLBACK TO SVPT1;
위와 같이 롤백(ROLLBACK)에 SAVEPOINT 명을 부여하여 실행하면 저장점 설정 이후에 있었던 데이터 변경에 대해서만 원래 데이터 상태로 되돌아가게 된다.
SQL Server는 SAVE TRANSACTION을 사용하여 동일한 기능을 수행할 수 있다.
다음의 SQL문은 SVTR1이라는 저장점을 정의하고 있다.
SAVE TRANSACTION SVTR1;
저장점까지 롤백할 때는 ROLLBACK 뒤에 저장점 명을 지정한다.
ROLLBACK TRANSACTION SVTR1;
그림에서 보듯이 저장점 A로 되돌리고 나서 다시 B와 같이 미래 방향으로 되돌릴 수는 없다.
일단 특정 저장점까지 롤백하면 그 저장점 이후에 설정한 저장점이 무효가 되기 때문이다.
즉, ‘ROLLBACK TO A’를 실행한 시점에서 저장점 A 이후에 정의한 저장점 B는 존재하지 않는다.
저장점 지정 없이 “ROLLBACK”을 실행했을 경우 반영안된 모든 변경 사항을 취소하고 트랜잭션 시작 위치로 되돌아간다.
정리
해당 테이블에 데이터의 변경을 발생시키는 입력(INSERT), 수정(UPDATE), 삭제(DELETE) 수행시 그 변경되는 데이터의 무결성을 보장하는 것이 커밋(COMMIT)과 롤백(ROLLBACK)의 목적이다.
저장점(SAVEPOINT/SAVE TRANSACTION)은 “데이터 변경을 사전에 지정한 저장점까지만 롤백하라”는 의미이다.
Oracle의 트랜잭션은 트랜잭션의 대상이 되는 SQL 문장을 실행하면 자동으로 시작되고, COMMIT 또는 ROLLBACK을 실행한 시점에서 종료된다.
단, 다음의 경우에는 COMMIT과 ROLLBACK을 실행하지 않아도 자동으로 트랜잭션이 종료된다.
가. CREATE, ALTER, DROP, RENAME, TRUNCATE TABLE 등 DDL 문장을 실행하면 그 전후 시점에 자동으로 커밋된다.
DML 문장 이후에 커밋 없이 DDL 문장이 실행되면 DDL 수행 전에 자동으로 커밋된다.
나. 데이터베이스를 정상적으로 접속을 종료하면 자동으로 트랜잭션이 커밋된다.
다. 애플리케이션의 이상 종료로 데이터베이스와의 접속이 단절되었을 때는 트랜잭션이 자동으로 롤백된다.
SQL Server의 트랜잭션은 DBMS가 트랜잭션을 컨트롤하는 방식인 AUTO COMMIT이 기본 방식이다. 다음의 경우는 Oracle과 같이 자동으로 트랜잭션이 종료된다.
애플리케이션의 이상 종료로 데이터베이스(인스턴스)와의 접속이 단절되었을 때는 트랜잭션이 자동으로 롤백된다.
2. WHERE 절
1) WHERE 조건절 개요
자료를 검색할 때 SELECT 절과 FROM 절만을 사용하여 기본적인 SQL 문장을 구성한다면, 테이블에 있는 모든 자료들이 결과로 출력되어 실제로 원하는 자료를 확인하기 어려울 수 있다.
사용자들은 자신이 원하는 자료만을 검색하기 위해서 SQL 문장에 WHERE 절을 이용하여 자료들에 대하여 제한할 수 있다.
WHERE 절에는 두 개 이상의 테이블에 대한 조인 조건을 기술하거나 결과를 제한하기 위한 조건을 기술할 수도 있다.
SELECT [DISTINCT/ALL] 칼럼명 [ALIAS명] FROM 테이블명 WHERE 조건식;
2) 연산자의 종류
만일 이러한 연산에 있어서 연산자들의 우선순위를 염두에 두지 않고 WHERE 절을 작성한다면 테이블에서 자기가 원하는 자료를 찾지 못하거나, 혹은 틀린 자료인지도 모른 채 사용할 수도 있다.
실수하기 쉬운 비교 연산자와 논리 연산자의 경우 괄호를 사용해서 우선순위를 표시하는 것을 권고한다.
3) SQL 연산자
SQL 연산자는 SQL 문장에서 사용하도록 기본적으로 예약되어 있는 연산자로서 모든 데이터 타입에 대해서 연산이 가능한 4가지 종류가 있다.
LIKE의 사전적 의미는 ‘~와 같다’이다.
만약 “장”씨 성을 가진 선수들을 조회할 경우는 어떻게 할까?
이런 문제를 해결하기 위해서 LIKE 연산자에서는 와일드카드(WildCard)를 사용할 수 있다.
와일드카드(WildCard)란 한 개 혹은 0개 이상의 문자를 대신해서 사용하기 위한 특수 문자를 의미하며, 이를 조합하여 사용하는 것도 가능하므로 SQL 문장에서 사용하는 스트링(STRING) 값으로 용이하게 사용할 수 있다.
[예제] “장”씨 성을 가진 선수들의 정보를 조회하는 WHERE 절을 작성한다.
[답안] SELECT PLAYER_NAME 선수이름
FROM PLAYER
WHERE PLAYER_NAME LIKE '장%';
NULL(ASCII 00)은 값이 존재하지 않는 것으로 확정되지 않은 값을 표현할 때 사용한다.
따라서 어떤 값보다 크거나 작지도 않고 ‘ ’(공백, ASCII 32)이나 0(Zero, ASCII 48)과 달리 비교 자체가 불가능한 값인 것이다.
연산 관련 NULL의 특성은 다음과 같다.
가. NULL 값과의 수치연산은 NULL 값을 리턴한다.
나. NULL 값과의 비교연산은 거짓(FALSE)을 리턴한다.
다. 어떤 값과 비교할 수도 없으며, 특정 값보다 크다, 적다라고 표현할 수 없다.
따라서 NULL 값의 비교는 비교 연산자인 “=”, “>”, “>=”, “<”, “=”를 통해서 비교할 수도 없고,
만일 비교 연산을 하게 되면 결과는 거짓(FALSE)을 리턴하고,
수치 연산자(+,-,*,/ 등)를 통해서 NULL 값과 연산을 하게 되면 NULL 값을 리턴한다.
NULL 값의 비교 연산은 IS NULL, IS NOT NULL 이라는 정해진 문구를 사용해야 제대로 된 결과를 얻을 수 있다.
4) 논리연산자
논리 연산자는 비교 연산자나 SQL 비교 연산자들로 이루어진 여러 개의 조건들을 논리적으로 연결시키기 위해서 사용되는 연산자이다.
논리 연산자들이 여러 개가 같이 사용되었을 때의 처리 우선순위는 ( ), NOT, AND, OR의 순서대로 처리된다.
5) 부정연산자
비교 연산자, SQL 비교 연산자에 대한 부정 표현을 부정 논리 연산자, 부정 SQL 연산자로 구분할 수 있다.
6) ROWNUM, TOP 사용
가. ROWNUM
Oracle의 ROWNUM은 칼럼과 비슷한 성격의 Pseudo Column으로써 SQL 처리 결과 집합의 각 행에 대해 임시로 부여되는 일련번호이며, 테이블이나 집합에서 원하는 만큼의 행만 가져오고 싶을 때 WHERE 절에서 행의 개수를 제한하는 목적으로 사용한다.
1건의 행만 가져오고 싶을 때는
SELECT PLAYER_NAME
FROM PLAYER
WHERE ROWNUM = 1;
추가적인 ROWNUM의 용도로는 테이블 내의 고유한 키나 인덱스 값을 만들 수 있다.
UPDATE MY_TABLE SET COLUMN1 = ROWNUM;
나. TOP 절
SQL Server는 TOP 절을 사용하여 결과 집합으로 출력되는 행의 수를 제한할 수 있다.
TOP 절의 표현식은 다음과 같다.
TOP (Expression) [PERCENT] [WITH TIES]
Expression : 반환할 행의 수를 지정하는 숫자이다.
PERCENT : 쿼리 결과 집합에서 처음 Expression%의 행만 반환됨을 나타낸다.
WITH TIES : ORDER BY 절이 지정된 경우에만 사용할 수 있으며,
TOP N(PERCENT)의 마지막 행과 같은 값이 있는 경우 추가 행이 출력되도록 지정할 수 있다.
그러나 일반적으로 데이터베이스라고 말할 때는 특정 기업이나 조직 또는 개인이 필요에 의해(ex: 부가가치가 발생하는) 데이터를 일정한 형태로 저장해 놓은 것을 의미한다. 예를 들어, 학교에서는 학생 관리를 목적으로 학생 개개인의 정보를 모아둘 것이고,
기업에서는 직원들을 관리하기 위해 직원들의 이름, 부서, 월급 등의 정보를 모아둘 것이다.
그리고 이러한 정보들을 관리하기 위해서 엑셀과 같은 소프트웨어를 이용하여 보기 좋게 정리하여 저장해 놓을 것이다. 그러나 관리 대상이 되는 데이터의 양이 점점 많아지고 같은 데이터를 여러 사람이 동시에 여러 용도로 사용하게 되면서 단순히 엑셀 같은 개인이 관리하는 소프트웨어 만으로는 한계에 부딪히게 된다.
또한 경우에 따라서는 개인의 사소한 부주의로 인해 기업의 사활이 걸린 중요한 데이터가 손상되거나 유실되는 상황이 발생할 수도 있다. 따라서 많은 사용자들은 보다 효율적인 데이터의 관리 뿐만 아니라 예기치 못한 사건으로 인한 데이터의 손상을 피하고, 필요시 필요한 데이터를 복구하기 위한 강력한 기능의 소프트웨어를 필요로 하게 되었고 이러한 기본적인 요구사항을 만족시켜주는 시스템을 DBMS(Database Management System)라고 한다.
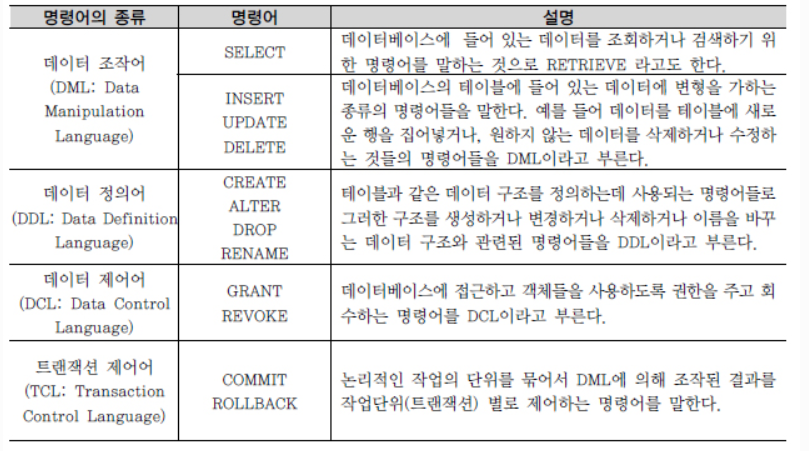
2) SQL(Structured Query Language)
SQL(Structured Query Language)은 관계형 데이터베이스에서 데이터 정의, 데이터 조작, 데이터 제어를 하기 위해 사용하는 언어이다. SQL의 문법이 영어 문법과 흡사하기 때문에 SQL 자체는 다른 개발 언어에 비해 기초 단계 학습은 쉬운 편이지만,
SQL이 시스템에 미치는 영향이 크므로 고급 SQL이나 SQL 튜닝의 중요성은 계속 커지고 있다.
SQL 문장은 단순 스크립트가 아니라 이름에도 포함되어 있듯이, 일반적인 개발 언어처럼 독립된 하나의 개발 언어이다. 하지만 일반적인 프로그래밍 언어와는 달리 SQL은 관계형 데이터베이스에 대한 전담 접속(다른 언어는 관계형 데이터베이스에 접속할 수 없다) 용도로 사용되며 집합 논리에 입각한 것이므로, SQL도 데이터를 집합으로써 취급한다. 예를 들어 ‘포지션이 미드필더(MF)인 선수의 정보를 검색한다’고 할 경우, 선수라는 큰 집합에서 포지션이 미드필더인 조건을 만족하는 요구 집합을 추출하는 조작이 된다. 이렇게 특정 데이터들의 집합에서 필요로 하는 데이터를 꺼내서 조회하고 새로운 데이터를 입력/수정/삭제하는 행위를 통해서 사용자는 데이터베이스와 대화하게 된다. 그리고 SQL은 이러한 대화를 가능하도록 매개 역할을 하는 것이다.
결과적으로 SQL 문장을 배우는 것이 곧 관계형 데이터베이스를 배우는 기본 단계라 할 수 있다.
SQL 문장의 종류는 다음과 같이 나누어진다.
이들 SQL 명령어는 3가지 SAVEPOINT 그룹인 DDL, DML, DCL로 나눌 수 있는데, TCL의 경우 굳이 나눈다면 일부에서 DCL로 분류하기도 하지만, 다소 성격이 다르므로 별도의 4번째 그룹으로 분리할 것을 권고한다.
3) 테이블( TABLE )
데이터는 관계형 데이터베이스의 기본 단위인 테이블 형태로 저장된다.
모든 자료는 테이블에 등록이 되고, 우리는 테이블로부터 원하는 자료를 꺼내 올 수 있다.
축구 선수의 정보를 정리한다고 했을 때 아래의 그림과 같으면 한 눈에 알아보기가 어렵다.
그렇기 때문에 이를 더 직관적으로 확인할 수 있게 데이터를 테이블화시켜서 정리한다.
테이블에는 등록된 자료들이 있으며, 이 자료들은 삭제하지 않는 한 지속적으로 유지된다. 만약 우리가 자료를 입력하지 않는다면 테이블은 본래 만들어졌을 때부터 가지고 있던 속성을 그대로 유지하면서 존재하게 된다.
테이블에 대해서 좀 더 상세히 살펴보면 테이블(TABLE)은 데이터를 저장하는 객체(Object)로서 관계형 데이터베이스의 기본 단위이다.
관계형 데이터베이스에서는 모든 데이터를 칼럼과 행의 2차원 구조로 나타낸다.
세로 방향을 칼럼(Column), 가로 방향을 행(Row)이라고 하고, 칼럼과 행이 겹치는 하나의 공간을 필드(Field)라고 한다. 선수정보 테이블을 예로 들면 선수명과 포지션 등의 칼럼이 있고, 각 선수에 대한 데이터를 행으로 구성하여 저장한다.
2. DDL ( Data Definition Language : 데이터 정의어 )
1) 데이터 유형
데이터 유형은 데이터베이스의 테이블에 특정 자료를 입력할 때, 그 자료를 받아들일 공간을 자료의 유형별로 나누는 기준이라고 생각하면 된다.
따라서 선언한 유형이 아닌 다른 종류의 데이터가 들어오려고 하면 데이터베이스는 에러를 발생시킨다.
예를 들어 선수의 몸무게 정보를 모아놓은 공간에 ‘박지성’이라는 문자가 입력되었을 때, 숫자가 의미를 가지는 칼럼 정보에 문자가 입력되었으니 잘못된 데이터라고 판단할 수 있는 것이다.
또한 데이터 유형과 더불어 지정한 크기(SIZE)도 중요한 기능을 제공한다.
2) CREATE TABLE
가. CREATE TABLE
테이블은 일정한 형식에 의해서 생성된다.
테이블 생성을 위해서는 해당 테이블에 입력될 데이터를 정의하고,
정의한 데이터를 어떠한 데이터 유형으로 선언할 것인지를 결정해야 한다.
테이블에 존재하는 모든 데이터를 고유하게 식별할 수 있으면서 반드시 값이 존재하는 단일 칼럼이나 칼럼의 조합들(후보키) 중에 하나를 선정하여 기본키 칼럼으로 지정한다.
그리고 테이블과 테이블 간에 정의된 관계는 기본키(PRIMARY KEY)와 외부키(FOREIGN KEY)를 활용해서 설정하도록 한다.
1. 테이블명은 객체를 의미할 수 있는 적절한 이름을 사용한다. 가능한 단수형을 권고한다.
2. 테이블 명은 다른 테이블의 이름과 중복되지 않아야 한다.
3. 한 테이블 내에서는 칼럼명이 중복되게 지정될 수 없다.
4. 테이블 이름을 지정하고 각 칼럼들은 괄호 "( )" 로 묶어 지정한다.
5. 각 칼럼들은 콤마 ","로 구분되고, 테이블 생성문의 끝은 항상 세미콜론 ";"으로 끝난다.
6. 칼럼에 대해서는 다른 테이블까지 고려하여 데이터베이스 내에서는 일관성 있게 사용하는 것이 좋다.(데이터 표준화 관점)
7. 칼럼 뒤에 데이터 유형은 꼭 지정되어야 한다.
8. 테이블명과 칼럼명은 반드시 문자로 시작해야 하고, 벤더별로 길이에 대한 한계가 있다.
9. 벤더에서 사전에 정의한 예약어(Reserved word)는 쓸 수 없다.
10. A-Z, a-z, 0 -9, _, $, # 문자만 허용된다.
아래 그림은 테이블 명명의 잘못 된 사례이다.
나. 제약조건( CONSTRAINT )
제약조건(CONSTRAINT)이란데이터의 무결성을 유지하기 위한 데이터베이스의 보편적인 방법이다.
테이블을 생성할 때 제약조건을 반드시 기술할 필요는 없지만,이후에ALTER TABLE을 이용해서 추가,수정하는 경우 데이터가 이미 입력된 경우라면 처리 과정이 쉽지 않으므로 초기 테이블 생성 시점부터 적합한 제약 조건에 대한 충분한 검토가 있어야 한다.
아래 그림은 제약조건의 종류이다.
3) ALTER TABLE
한 번 생성된 테이블은 특별히 사용자가 구조를 변경하기 전까지 생성 당시의 구조를 유지하게 된다.
처음의 테이블 구조를 그대로 유지하는 것이 최선이지만, 업무적인 요구 사항이나 시스템 운영상 테이블을 사용하는 도중에 변경해야 할 일들이 발생할 수도 있다.
이 경우 주로 칼럼을 추가/삭제하거나 제약조건을 추가/삭제하는 작업을 진행하게 된다.
가.ADD COLUMN
다음은 기존 테이블에 필요한 칼럼을 추가하는 명령이다.
주의할 것은 새롭게 추가된 칼럼은 테이블의 마지막 칼럼이 되며 칼럼의 위치를 지정할 수는 없다.
[예제] PLAYER 테이블에 ADDRESS(데이터 유형은 가변 문자로 자릿수 80자리로 설정한다.) 칼럼을 추가한다.
[답안] Oracle ALTER TABLE PLAYER ADD (ADDRESS VARCHAR2(80));
나.DROP COLUMN
DROP COLUMN은 테이블에서 필요 없는 칼럼을 삭제할 수 있으며, 데이터가 있거나 없거나 모두 삭제 가능하다.
한 번에 하나의 칼럼만 삭제 가능하며, 칼럼 삭제 후 최소 하나 이상의 칼럼이 테이블에 존재해야 한다.
주의할 부분은 한 번 삭제된 칼럼은 복구가 불가능하다. 다음은 테이블의 불필요한 칼럼을 삭제하는 명령이다.
[예제] 앞에서 PLAYER 테이블에 새롭게 추가한 ADDRESS 칼럼을 삭제한다.
[답안] Oracle ALTER TABLE PLAYER DROP COLUMN ADDRESS;
다.MODIFY COLUMN
테이블에 존재하는 칼럼에 대해서 ALTER TABLE 명령을 이용해 칼럼의 데이터 유형, 디폴트(DEFAULT) 값, NOT NULL 제약조건에 대한 변경을 포함할 수 있다. 다음은 테이블의 칼럼에 대한 정의를 변경하는 명령이다.
칼럼을 변경할 때는 몇 가지 사항을 고려해서 변경해야 한다.
1.해당 칼럼의 크기를 늘릴 수는 있지만 줄이지는 못한다. 이는 기존의 데이터가 훼손될 수 있기 때문이다.
2.해당 칼럼이 NULL 값만 가지고 있거나 테이블에 아무 행도 없으면 칼럼의 폭을 줄일 수 있다.
3.해당 칼럼이 NULL 값만을 가지고 있으면 데이터 유형을 변경할 수 있다.
4.해당 칼럼의 DEFAULT 값을 바꾸면 변경 작업 이후 발생하는 행 삽입에만 영향을 미치게 된다.
5.해당 칼럼에 NULL 값이 없을 경우에만 NOT NULL 제약조건을 추가할 수 있다.
[예제] TEAM 테이블의 ORIG_YYYY 칼럼의 데이터 유형을 CHAR(4)→VARCHAR2(8)으로 변경하고, 향후 입력되는 데이터의 DEFAULT 값으로 '20020129'을 적용하고, 모든 행의 ORIG_YYYY 칼럼에 NULL이 없으므로 제약조건을 NULL → NOT NULL로 변경한다.
[답안] Oracle ALTER TABLE TEAM_TEMP MODIFY (ORIG_YYYY VARCHAR2(8) DEFAULT '20020129' NOT NULL);
라.RENAME COLUMN
테이블을 생성하면서 만들어졌던 칼럼명을 어떤 이유로 불가피하게 변경해야 하는 경우에 유용하게 쓰일 수 있는 RENAME COLUMN 문구이다.
ALTER TABLE 테이블명 RENAME COLUMN 변경해야 할 칼럼명 TO 새로운 칼럼명;
ALTER TABLE PLAYER RENAME COLUMN PLAYER_ID TO TEMP_ID;
마.DROP CONSTRAINT.
테이블 생성 시 부여했던 제약조건을 삭제하는 명령어 형태는 다음과 같다.
ALTER TABLE 테이블명 DROP CONSTRAINT 제약조건명;
[예제] PLAYER 테이블의 외래키 제약조건을 삭제한다.
[답안] Oracle ALTER TABLE PLAYER DROP CONSTRAINT PLAYER_FK;
바. ADD CONSTRAINT
테이블 생성 시 제약조건을 적용하지 않았다면, 생성 이후에 필요에 의해서 제약조건을 추가할 수 있다. 다음은 특정 칼럼에 제약조건을 추가하는 명령어 형태이다.
.
ALTER TABLE 테이블명 ADD CONSTRAINT 제약조건명 제약조건 (칼럼명);
[예제] PLAYER 테이블에 TEAM 테이블과의 외래키 제약조건을 추가한다. 제약조건명은 PLAYER_FK로 하고, PLAYER 테이블의 TEAM_ID 칼럼이 TEAM 테이블의 TEAM_ID를 참조하는 조건이다.
[답안] ALTER TABLE PLAYER ADD CONSTRAINT PLAYER_FK FOREIGN KEY (TEAM_ID) REFERENCES TEAM(TEAM_ID); 테이블이 변경되었다.
[예제] PLAYER 테이블이 참조하는 TEAM 테이블을 제거해본다.
[답안] DROP TABLE TEAM; ERROR: 외래 키에 의해 참조되는 고유/기본 키가 테이블에 있다. ※ 테이블은 삭제되지 않음
[예제] PLAYER 테이블이 참조하는 TEAM 테이블의 데이터를 삭제해본다.
[답안] DELETE TEAM WHERE TEAM_ID = 'K10'; ERROR: 무결성 제약조건
(SCOTT.PLAYER_FK)이 위배되었다. 자식 레코드가 발견되었다. ※ 데이터는 삭제되지 않음
위와 같이 참조 제약조건을 추가하면 PLAYER 테이블의 TEAM_ID 칼럼이 TEAM 테이블의 TEAM_ID 칼럼을 참조하게 된다. 참조 무결성 옵션에 따라서 만약 TEAM 테이블이나 TEAM 테이블의 데이터를 삭제하려 할 경우 외부(PLAYER 테이블)에서 참조되고 있기 때문에 삭제가 불가능하게 제약을 할 수 있다.
즉, 외부키(FK)를 설정함으로써 실수에 의한 테이블 삭제나 필요한 데이터의 의도하지 않은 삭제와 같은 불상사를 방지하는 효과를 볼 수 있다.
4)RENAME TABLE
RENAME 명령어를 사용하여 테이블의 이름을 변경할 수 있다.
RENAME 변경전 테이블명 TO 변경후 테이블명;
[예제] RENAME 문장을 이용하여 TEAM 테이블명을 다른 이름으로 변경하고, 다시 TEAM 테이블로 변경한다.
[답안] RENAME TEAM TO TEAM_BACKUP;
RENAME TEAM_BACKUP TO TEAM;
5)DROP TABLE
테이블을 잘못 만들었거나 테이블이 더 이상 필요 없을 경우 해당 테이블을 삭제해야 한다. 다음은 불필요한 테이블을 삭제하는 명령이다.
DROP TABLE 테이블명 [CASCADE CONSTRAINT];
DROP 명령어를 사용하면 테이블의 모든 데이터 및 구조를 삭제한다. CASCADE CONSTRAINT 옵션은 해당 테이블과 관계가 있었던 참조되는 제약조건에 대해서도 삭제한다는 것을 의미한다. SQL Server에서는 CASCADE 옵션이 존재하지 않으며 테이블을 삭제하기 전에 참조하는 FOREIGN KEY 제약 조건 또는 참조하는 테이블을 먼저 삭제해야 한다.
6)TRUNCATE TABLE
TRUNCATE TABLE은 테이블 자체가 삭제되는 것이 아니고, 해당 테이블에 들어있던 모든 행들이 제거되고 저장 공간을 재사용 가능하도록 해제한다. 테이블 구조를 완전히 삭제하기 위해서는 DROP TABLE을 실행하면 된다.
TRUNCATE TABLE PLAYER;
DROP TABLE의 경우는 테이블 자체가 없어지기 때문에 테이블 구조를 확인할 수 없다.
반면 TRUNCATE TABLE의 경우는 테이블 구조는 그대로 유지한 체 데이터만 전부 삭제하는 기능이다.
TRUNCATE는 데이터 구조의 변경 없이 테이블의 데이터를 일괄 삭제하는 명령어로 DML로 분류할 수도 있지만 내부 처리 방식이나 Auto Commit 특성 등으로 인해 DDL로 분류하였다.
테이블에 있는 데이터를 삭제하는 명령어는 TRUNCATE TABLE 명령어 이외에도 다음 DML 절에서 살펴볼 DELETE 명령어가 있다.
그러나 DELETE와 TRUNCATE는 처리하는 방식 자체가 다르다.
테이블의 전체 데이터를 삭제하는 경우, 시스템 활용 측면에서는 DELETE TABLE 보다는 시스템 부하가 적은 TRUNCATE TABLE을 권고한다.
단, TRUNCATE TABLE의 경우 정상적인 복구가 불가능하므로 주의해야 한다.
2. DML ( Data Manipulation Language : 데이터 조작어 )
1) INSERT
DML은 만들어진 테이블에 관리하기를 원하는 자료들을 입력, 수정, 삭제, 조회하는 SQL이다.
테이블에 데이터를 입력하는 방법은 두 가지 유형이 있으며 한 번에 한 건만 입력된다.
INSERT INTO 테이블명 (COLUMN_LIST)VALUES (COLUMN_LIST에 넣을 VALUE_LIST);
INSERT INTO 테이블명 VALUES (전체 COLUMN에 넣을 VALUE_LIST);
첫 번째 유형은 테이블의 칼럼을 정의할 수 있는데, 이때 칼럼의 순서는 테이블의 칼럼 순서와 매치할 필요는 없으며, 정의하지 않은 칼럼은 Default로 NULL 값이 입력된다.
단, Primary Key나 Not NULL 로 지정된 칼럼은 NULL이 허용되지 않는다.
두 번째 유형은 모든 칼럼에 데이터를 입력하는 경우로 굳이 COLUMN_LIST를 언급하지 않아도 되지만, 칼럼의 순서대로 빠짐없이 데이터가 입력되어야 한다.
1.해당 칼럼명과 입력되어야 하는 값을 서로 1:1로 매핑해서 입력하면 된다.
2.해당 칼럼의 데이터 유형이 CHAR나 VARCHAR2 등 문자 유형일 경우 『 ' 』(SINGLE QUOTATION)로 입력할 값을 입력한다.
3.숫자일 경우 『 ' 』(SINGLE QUOTATION)을 붙이지 않아야 한다.
2) UPDATE
입력한 정보 중에 잘못 입력되거나 변경이 발생하여 정보를 수정해야 하는 경우가 발생할 수 있다.
UPDATE 다음에 수정되어야 할 칼럼이 존재하는 테이블명을 입력하고 SET 다음에 수정되어야 할 칼럼명과 해당 칼럼에 수정되는 값으로 수정이 이루어진다.
UPDATE 테이블명 SET 수정되어야 할 칼럼명 = 수정되기를 원하는 새로운 값;
[예제] 선수 테이블의 백넘버를 일괄적으로 99로 수정한다.
[정답] UPDATE PLAYER SET BACK_NO = 99;
3) DELETE
테이블의 정보가 필요 없게 되었을 경우 데이터 삭제를 수행한다.
DELETE FROM 다음에 삭제를 원하는 자료가 저장되어 있는 테이블명을 입력하고 실행한다.
이때 FROM 문구는 생략이 가능한 키워드이며, 뒤에서 배울 WHERE 절을 사용하지 않는다면 테이블의 전체 데이터가 삭제된다.
DELETE [FROM] 삭제를 원하는 정보가 들어있는 테이블명;
[예제] 선수 테이블의 데이터를 전부 삭제한다.
[정답] DELETE FROM PLAYER;
참고로 데이터베이스는 DDL 명령어와 DML 명령어를 처리하는 방식에 있어서 차이를 보인다. DDL(CREATE, ALTER, RENAME, DROP) 명령어인 경우에는 직접 데이터베이스의 테이블에 영향을 미치기 때문에 DDL 명령어를 입력하는 순간 명령어에 해당하는 작업이 즉시(AUTO COMMIT) 완료된다.
하지만 DML(INSERT, UPDATE, DELETE, SELECT) 명령어의 경우, 조작하려는 테이블을 메모리 버퍼에 올려놓고 작업을 하기 때문에 실시간으로 테이블에 영향을 미치는 것은 아니다. 따라서 버퍼에서 처리한 DML 명령어가 실제 테이블에 반영되기 위해서는 COMMIT 명령어를 입력하여 TRANSACTION을 종료해야 한다.
테이블의 전체 데이터를 삭제하는 경우, 시스템 활용 측면에서는 삭제된 데이터를 로그로 저장하는 DELETE TABLE 보다는 시스템 부하가 적은 TRUNCATE TABLE을 권고한다. 단, TRUNCATE TABLE의 경우 삭제된 데이터의 로그가 없으므로 ROLLBACK이 불가능하므로 주의해야 한다.
4) SELECT
사용자가 입력한 데이터는 언제라도 조회가 가능하다.
앞에서 입력한 자료들을 조회해보는 SQL 문은 다음과 같다.
[예제] 입력한 선수들의 정보를 모두 조회한다.
[답안] SELECT * FROM PLAYER;
해당 테이블의 모든 칼럼 정보를 보고 싶을 경우에는 와일드카드로 애스터리스크(*)를 사용하여 조회할 수 있다.
[예제] 조회하기를 원하는 칼럼명을 SELECT 다음에 콤마 구분자(,)로 구분하여 나열하고, FROM 다음에 해당 칼럼이 존재하는 테이블명을 입력하여 실행시킨다. 입력한 선수들의 데이터를 조회한다.
Extended ER모델이라고 부르는 이른바 슈퍼/서브타입 데이터 모델은 최근에 데이터 모델링을 할 때 자주 쓰이는 모델링 방법이다.
이 모델이 장점은 데이터의 특징의 공통점과 차이점을 고려하여 효과적으로 표현할 수 있다는 것이다.
즉, 공통의 부분을 슈퍼타입으로 모델링하고 공통으로부터 상속받아 다른 엔터티와 차이가 있는 속성에 대해서는 별도의 서브엔터티로 구분하여 업무의 모습을 정확하게 표현하면서 물리적인 데이터 모델로 변환을 할 때 선택의 폭을 넓힐 수 있는 장점이 있다.
이러한 장점 때문에 많은 프로젝트에서 슈퍼/서브타입을 활용한 데이터 모델의 사례가 증가하고 있다. 당연히 슈퍼/서브타입의 데이터 모델은 논리적 데이터 모델에서 이용되는 형태이고 분석/설계단계를 구분하자면, 분석단계에서 많이 쓰이는 모델이다. 따라서 물리적인 데이터 모델을 설계하는 단계에서는 슈퍼/서브타입 데이터 모델을 일정한 기준에 의해 변환을 해야 한다.
나. 슈퍼/서브타입 데이터 모델의 변환
성능을 고려한 슈퍼타입과 서브타입의 모델 변환의 방법을 알아보면 그림과 같다.
슈퍼/서브타입 변환시 성능이 저하되는 이유
트랜잭션 특성을 고려하지 않고 테이블이 설계되었기 때문이다.
1> 트랜잭션은 항상 일괄로 처리하는데 테이블은 개별로 유지되어 Union연산에 의해 성능이 저하될 수 있다.
2> 트랜잭션은 항상 서브타입 개별로 처리하는데 테이블은 하나로 통합되어 있어 불필요하게 많은 양의 데이터가 집약되어 있어 성능이 저하되는 경우가 있다.
3> 트랜잭션은 항상 슈퍼+서브 타입을 공통으로 처리하는데 개별로 유지되어 있거나 하나의 테이블로 집약되어 있어 성능이 저하되는 경우가 있다.
해당 테이블에 발생되는 성능이 중요한 트랜잭션이 빈번하게 처리되는 기준에 따라 테이블을 설계해야 이러한 성능저하 현상을 예방할 수 있음을 기억해야 한다.
슈퍼/서브타입을 성능을 고려한 물리적인 데이터 모델로 변환하는 기준은 데이터 양과 해당 테이블에 발생되는 트랜잭션의 유형에 따라 결정된다.
데이터량이 소량일 경우 성능에 영향을 미치지 않기 때문에 데이터처리의 유연성을 고려하여 1:1 관계를 유지한다.
그러나 데이터용량이 많아지는 경우 그리고 해당 업무적인 특징이 성능에 민감한 경우는 트랜잭션이 해당 테이블에 어떻게 발생되는지에 따라 3가지 변환방법을 참조하여 상황에 맞게 변환하도록 해야 한다.
다. 슈퍼/서브 타입 데이터 모델의 변환기술
논리적인 데이터 모델에서 설계한 슈퍼타입/서브타입 모델을 물리적인 데이터 모델로 전환할 때 주로 어떤 유형의 트랜잭션이 발생하는지 검증해야 한다.
물론 데이터량이 아주 작다면, 예를 들어 10만 건도 되지 않고, 시스템을 운영하는 중에도 증가하지 않는다면 트랜잭션의 성격을 고려하지 않고 전체를 하나의 테이블로 묶어도 좋은 방법이다. 그러나 데이터량이 많이 존재하고 지속적으로 증가하는 양도 많다면 슈퍼타입/서브타입에 대해 물리적인 데이터 모델로 변환하는 세 가지 유형에 대해 세심하게 적용을 해야 한다.
1> 개별로 발생되는 트랜잭션에 대해서는 개별 테이블로 구성 업무적으로 발생되는 트랜잭션이 슈퍼타입과 서브타입 각각에 대해 발생하는 것이다. 그림의 업무화면을 보면 공통으로 처리하는 슈퍼타입테이블인 당사자 정보를 미리 조회하고 원하는 내용을 클릭하면 거기에 따라서 서브타입인 세부적인 정보 즉 이해관계인, 매수인, 대리인에 대한 내용을 조회하는 형식이다.
즉 슈퍼타입이 각 서브타입에 대해 기준역할을 하는 형식으로 사용할 때 이러한 유형의 트랜잭션이 발생이 된다.
위와 같이 슈퍼타입과 서브타입각각에 대해 독립적으로 트랜잭션이 발생이 되면 슈퍼타입에도 꼭 필요한 속성만을 가지게 하고 서브타입에도 꼭 필요한 속성 및 자신이 타입에 맞는 데이터만 가지게 하기 위해서 모두 분리하여 1:1 관계를 갖도록 한다.
실전프로젝트에서는 데이터량이 대용량으로 존재하는 경우에 공통으로 이용하는 슈퍼타입의 속성의 수가 너무 많아져 디스크 I/O가 많아지는 것을 방지하기 위해 위와 같이 각각을 1:1 관계로 가져가는 경우도 있다.
2> 슈퍼타입+서브타입에 대해 발생되는 트랜잭션에 대해서는 슈퍼타입+서브타입 테이블로 구성 만약 대리인이 10만 건, 매수인 500만 건, 이해관계인 500만 건의 데이터가 존재한다고 가정하고
슈퍼타입과 서브타입이 모두 하나의 테이블로 통합되어 있다고 가정하자.
매수인, 이해관계인에 대한 정보는 배제하고 10만 건뿐인 대리인에 대한 데이터만 처리할 경우 다른 테이블과 같이 데이터가 저장되어 있는 곳에서 처리해야 하므로 불필요한 성능저하 현상이 유발된다.
즉 대리인에 대한 처리가 개별적으로 많이 발생하는데 매수인과 이해관계인의 데이터까지 포함되어 있으므로 최대 10만 건을 읽어 처리할 수 있는 업무가 최대 1010만 건을 읽어 처리하는 경우가 발생될 수 있다. 이와 같이 슈퍼타입과 서브타입을 묶어 트랜잭션이 발생하는 업무특징을 가지고 있을 때에는 다음 데이터 모델과 같이 슈퍼타입+각서브타입을 하나로 묶어 별도의 테이블로 구성하는 것이 효율적이다.
3> 전체를 하나로 묶어 트랜잭션이 발생할 때는 하나의 테이블로 구성 대리인 10만 건, 매수인 500만 건, 이해관계인 500만 건의 데이터가 존재한다고 하더라도 데이터를 처리할 때 대리인, 매수인, 이해관계인을 항상 통합하여 처리한다고 하면 테이블을 개별로 분리해야 불필요한 조인을 유발하거나 불필요한 UNION ALL과 같은 SQL구문이 작성되어 성능이 저하된다. 비록 슈퍼타입과 서브타입의 테이블들을 하나로 묶었을 때 각각의 속성별로 제약사항(NULL/NOT NULL, 기본값, 체크값)을 정확하게 지정하지 못할지라도 대용량이고 성능향상이 필요하다면 하나의 테이블로 묶어서 만들어 준다.
3가지 전개 방식이 아주 간단한 원리 같은데 이것도 실전 프로젝트에서 적용하면 쉽지 않은 경우가 많이 나타난다. 때로는 각각의 유형이 혼합되어 있는 경우도 있다. 혼합된 트랜잭션 유형이 있는 경우는 많이 발생하는 트랜잭션 유형에 따라 구성하면 된다.
라. 슈퍼/서브타입 데이터 모델의 변환타입 비교
2) 인덱스 특성을 고려한 PK/FK 데이터베이스 성능향상
가. PK/FK 컬럼 순서와 성능개요
데이터를 조회할 때 가장 효과적으로 처리될 수 있도록 접근경로를 제공하는 오브젝트가 바로 인덱스이다.
일반적으로 데이터베이스 테이블에서는 균형 잡힌 트리구조의 B*Tree구조를 많이 사용한다.
우리는 B*Tree구조의 내부 알고리즘까지는 알 필요가 없더라도 그 구조를 이용할 때 정렬되어 있는 특징으로 인해 데이터베이스 설계에 이 특징에 따라 설계에 반영해야 할 요소에 대해서는 반드시 알고 있어야 좋은 데이터 모델을 만들어 낼 수 있게 된다. 프로젝트에서 PK/FK설계는 업무적 의미로도 매우 중요한 의미를 가지고 있지만 데이터를 접근할 때 경로를 제공하는 성능의 측면에서도 중요한 의미를 가지고 있기 때문에 성능을 고려한 데이터베이스 설계가 될 수 있도록 설계단계 말에 컬럼의 순서를 조정할 필요가 있다.
간단한 것 같지만 실전 프로젝트에서는 아주 중요한 내용이 바로 PK순서이다.
성능저하 현상의 많은 부분이 PK가 여러 개의 속성으로 구성된 복합식별자 일 때 PK순서에 대해 별로 고려하지 않고 데이터 모델링을 한 경우에 해당된다.
특히 물리적인 데이터 모델링 단계에서는 스스로 생성된 PK순서 이외에 다른 엔터티로부터 상속받아 발생되는 PK순서까지 항상 주의하여 표시하도록 해야 한다.
PK는 해당 해당테이블의 데이터를 접근할 가장 빈번하게 사용되는 유일한 인덱스(Unique Index)를 모두 자동 생성한다. PK순서를 결정하는 기준은 인덱스 정렬구조를 이해한 상태에서 인덱스를 효율적으로 이용할 수 있도록 PK순서를 지정해야 한다.
즉 인덱스의 특징은 여러 개의 속성이 하나의 인덱스로 구성되어 있을 때 앞쪽에 위치한 속성의 값이 비교자로 있어야 인덱스가 좋은 효율을 나타낼 수 있다. 앞쪽에 위치한 속성 값이 가급적 ‘=’ 아니면 최소한 범위 ‘BETWEEN’ ‘< >’가 들어와야 인덱스를 이용할 수 있는 것이다. 데이터 모델링 때 결정한 PK순서와는 다르게 DDL문장을 통해 PK순서를 다르게 생성할 수도 있다.
그러나 대부분의 프로젝트에서는 데이터 모델의 PK 순서에 따라 그대로 PK를 생성한다.
만약 다르게 생성한다고 하더라도 데이터 모델과 데이터베이스 테이블의 구조가 다른 것처럼 보여 유지보수에 어려움이 많을 것이다. 또한 FK라고 하더라도 데이터를 조회할 때 조인의 경로를 제공하는 역할을 수행하므로 FK에 대해서는 반드시 인덱스를 생성하도록 하고 인덱스 칼럼의 순서도 조회의 조건을 고려하여 접근이 가장 효율적인 칼럼 순서대로 인덱스를 생성하도록 주의해야 한다.
나. PK컬럼의 순서를 조정하지 않으면 성능이 저하되는 이유
먼저 데이터 모델링에서 엔티티를 설계하고,
그에 따라 DDL이 생성이 되고 생성된 DDL에 따라 인덱스가 생성된다.
이 때 우리가 알아야 할 구조는 인덱스의 정렬구조에 해당된다.
그림은 인덱스의 정렬구조가 생성되는 구조를 보여주고 있다.
그림에서 보면 테이블에서 데이터 모델의 PK순서에 따라 DDL이 그대로 생성이 되고 테이블의 데이터가 주문번호가 가장먼저 정렬되고 그에 따라 주문일자가 정렬이 되고 마지막으로 주문목록코드가 정렬되는 것을 알 수 있다. 이러한 정렬 구조로 인해 데이터를 접근하는 트랜잭션의 조건에 따라 다른 인덱스 접근방식을 보여주게 된다. 위와 같은 인덱스의 정렬 구조에서 SQL구문의 조건에 따라 인덱스를 처리하는 범위가 달라지게 된다. 맨 앞에 있는 인덱스 칼럼에 대해 조회 조건이 들어올 때 데이터를 접근하는 방법은 다음 그림과 같다.
인덱스의 정렬된 첫 번째 칼럼에 비교가 되었기 때문에 순차적으로 데이터를 찾아가게 된다. 맨 앞에 있는 칼럼이 제외된 상태에서 데이터를 조회 할 경우 데이터를 비교하는 범위가 매우 넓어지게 되어 성능 저하를 유발하게 된다.
그림의 예에서는 주문번호에 대한 비교값이 들어오지 않으므로 인해 인덱스 전체를 읽어야만 원하는 데이터를 찾을 수 있게 된다. 이러한 이유로 인덱스를 읽고 테이블 블록에서 읽어 처리하는데 I/O가 많이 발생하게 되므로 옵티마이저는 차라리 테이블에 가서 전체를 읽는 방식으로 처리하게 된다. 이러한 모습으로 인덱스의 정렬구조를 이해한 상태에서 인덱스에 접근하는 접근유형을 비교해보면 어떠한 인덱스를 태워야 하는지 어떠한 조건이 들어와야 데이터를 처리하는 양을 줄여 성능을 향상시킬 수 있는지 알 수 있게 된다.
1> PK의 순서를 인덱스 특징에 맞게 고려하지 않고 바로 그대로 생성.
2> 테이블에 접근하는 트랜잭션의 특징에 효율적이지 않은 인덱스가 생성되어있음.
3> 인덱스의 범위를 넓게 이용하거나 Full Scan을 유발하게 되어 성능이 저하.
2. 분산 데이터베이스와 성능
1) 분산 데이터베이스의 정의
가. 여러 곳으로 분산되어있는 데이터베이스를 하나의 가상 시스템으로 사용할 수 있도록 한 데이터베이스.
나. 논리적으로 동일한 시스템에 속하지만, 컴퓨터 네트워크를 통해 물리적으로 분산되어 있는 데이터들의 모임.
물리적 Site 분산, 논리적으로 사용자 통합·공유
즉, 분산 데이터베이스는 데이터베이스를 연결하는 빠른 네트워크 환경을 이용하여 데이터베이스를 여러 지역 여러 노드로 위치시켜 사용성/성능 등을 극대화 시킨 데이터베이스라고 정의할 수 있다.
2) 분산 데이터베이스의 투명성(Transparency)
투명성 (Transparency) 이란?
공학적으로는 세부사항을 숨겨서 보이지 않게 하여 (마치 투명하게) 관리의 용이성을 증대시키는 등의 기술을 말함
가. 분할 투명성 (단편화) : 하나의 논리적 Relation이 여러 단편으로 분할되어 각 단편의 사본이 여러 장소에 저장 나. 위치 투명성 : 사용하려는 데이터의 저장 장소 명시 불필요. 위치정보가 System Catalog에 유지되어야 함 다. 지역사상 투명성 : 지역DBMS와 물리적 DB사이의 Mapping 보장. 각 지역시스템 이름과 무관한 이름 사용 가능 라. 중복 투명성 : DB 객체가 여러 site에 중복 되어 있는지 알 필요가 없는 성질 마. 장애 투명성 : 구성요소(DBMS, Computer)의 장애에 무관한 Transaction의 원자성 유지 바. 병행 투명성 : 다수 Transaction 동시 수행시 결과의 일관성 유지, Time Stamp, 분산 2단계 Locking을 이용 구현
3) 분산 데이터베이스의 적용 방법 및 장단점
가. 분산 데이터베이스 적용방법
분산 환경의 데이터베이스를 성능이 우수하게 현장에서 가치 있게 사용하는 방법은 업무의 흐름을 보고 업무구성에 따른 아키텍처 특징에 따라 데이터베이스를 구성하는 것이다. 단순히 분산 환경에서 데이터베이스를 구축하는 것이 목적이 아니라, 업무의 특징에 따라 데이터베이스 분산구조를 선택적으로 설계하는 능력이 필요한 것이다.
이러한 측면만을 보았을 때는 데이터베이스 분산설계라는 측면보다는 데이터베이스 구조설계(아키텍처)라는 의미로 이해해도 무방할 것이다.
나. 분산 데이터베이스 장단점
4) 분산 데이터베이스의 활용 방향성
분산 데이터베이스는 업무적인 기능이 다양해지고 데이터의 양이 기하급수적으로 증가하는 최근 데이터베이스 환경에서 적용하는 고급화된 기술이다.
업무적인 특징에 따라 분산 데이터베이스를 활용하는 기술이 필요하다.
5) 데이터베이스 분산구성의 가치
데이터를 분산 환경으로 구성하였을 때 가장 핵심적인 가치는 통합된 데이터베이스에서 제공할 수 없는 빠른 성능을 제공한다는 점이다. 원거리 또는 다른 서버에 접속하여 처리하므로 인해 발생되는 네트워크 부하 및 트랜잭션 집중에 따른 성능 저하의 원인을 분산된 데이터베이스 환경을 구축하므로 빠른 성능을 제공하는 것이 가능해 진다.
바로 이 점 때문에 분산 환경의 데이터베이스를 구축하게 되는 것이다.
6) 분산 데이터베이스의 적용 기법
데이터베이스의 분산의 종류에는
가. 테이블 위치 분산
나. 테이블 분할 분산
다. 테이블 복제 분산
라. 테이블 요약 분산
그 중에서도 가장 많이 사용하는 방식의 테이블의 복제 분할 분산의 방법이고 이 방법은 성능이 저하되는 많은 데이터베이스에서 가장 유용하게 적용할 수 있는 기술적인 방법이 된다.
분산 환경으로 데이터베이스를 설계하는 방법은 일단 통합 데이터 모델링을 하고 각 테이블별로 업무적인 특징에 따라 지역 또는 서버별로 테이블을 분산 배치나 복제 배치하는 형태로 설계할 수 있다.
가. 테이블 위치 분산
테이블 위치 분산은 테이블의 구조는 변하지 않는다.
또한 테이블이 다른 데이터베이스에 중복되어 생성되지도 않는다.
다만 설계된 테이블의 위치를 각각 다르게 위치시키는 것이다.
예를 들어, 자재품목은 본사에서 구입하여 관리하고 각 지사별로 자재품목을 이용하여 제품을 생산한다고 하면 그림과 같이 데이터베이스를 본사와 지사단위로 분산시킬 수 있다.
테이블의 위치가 위치별로 다르므로 테이블의 위치를 파악할 수 있는 도식화된 위치별 데이터베이스 문서가 필요하다.
나. 테이블 분할(Fragmentation) 분산
테이블 분할 분산은 단순히 위치만 다른 곳에 두는 것이 아니라 각각의 테이블을 쪼개어 분산하는 방법이다.
테이블을 분할하여 분산하는 방법은 테이블을 나누는 기준에 따라 두 가지로 구분된다.
첫 번째는 테이블의 로우(Row)단위로 분리하는 수평분할(Horizontal Fragmentation)
두 번째는 테이블을 칼럼(Column) 단위로 분할하는 수직분할(Vertical Fragmentation)
수평분할(Horizontal Fragmentation)
지사(Node)에 따라 테이블을 특정 칼럼의 값을 기준으로 로우(Row)를 분리한다. 칼럼은 분리되지 않는다.
모든 데이터가 각 지사별로 분리되어 있는 형태를 가지고 있다.
데이터를 한군데 집합시켜 놓아도 Primary Key에 의해 중복이 발생되지 않는다.
이와 같이 수평분할을 이용하는 경우는 각 지사(Node)별로 사용하는 로우(Row)가 다를 때 이용한다. 데이터를 수정할 때는 타 지사에 있는 데이터를 원칙적으로 수정하지 않고 자신의 데이터에 대해서 수정하도록 한다. 각 지사에 존재하는 테이블에 대해서 통합처리를 해야 하는 경우는 조인(JOIN)이 발생하여 성능 저하가 예상되므로 통합처리 프로세스가 많은지를 먼저 검토한 이후에 많지 않은 경우에 수평분할을 해야 한다. 데이터가 지사별로 별도로 존재하므로 중복은 발생하지 않는다.
대신 타 지사에 있는 데이터가 지사구분이 변경되면 단순히 수정이 발생하는 것 이외에 변경된 지사로 데이터를 이송해야 한다. 한 시점에는 한 지사(Node)에서 하나의 데이터만이 존재하므로 데이터의 무결성은 보장되는 형태이다. 지사(Node)별로 데이터베이스를 운영하는 경우는 데이터베이스가 속한 서버가 지사(Node)에 존재하던지 아니면 본사에 통합해서 존재하건 간에 데이터베이스 테이블들은 수평 분할하여 존재한다.
수직분할(Vertical Fragmentation)
지사(Node)에 따라 테이블 칼럼을 기준으로 컬럼을 분리한다.
로우(Row) 단위로는 분리되지 않는다.
모든 데이터가 각 지사별로 분리되어 있는 형태를 가지고 있다.
칼럼을 기준으로 분할하였기 때문에 각각의 테이블에는 동일한 Primary Key구조와 값을 가지고 있어야 한다.
지사별로 쪼개어진 테이블들을 조합하면 Primary Key가 동일한 데이터의 조합이 가능해야 하며 하나의 완전한 테이블이 구성되어야 한다.
데이터를 한군데 집합시켜 놓아도 동일한 Primary Key는 하나로 표현하면 되므로 데이터 중복은 발생되지 않는다.
예를 들어 제품의 재고량은 각 지사별로 관리하고 제품에 대한 단가는 본사에서 관리한다고 하면 본사 테이블에는 제품번호, 단가가 존재하고 지사에는 제품번호, 재고량이 존재한다.
다. 테이블 복제 분산
테이블 복제(Replication) 분산은 동일한 테이블을 다른 지역이나 서버에서 동시에 생성하여 관리하는 유형이다.
1>마스터 데이터베이스에서 테이블의 일부의 내용만 다른 지역이나 서버에 위치시키는 부분복제(Segment Replication)
2>마스터 데이터베이스의 테이블의 내용을 각 지역이나 서버에 존재시키는 광역복제(Broadcast Replication)
1>부분복제(Segment Replication)
통합된 테이블을 한군데(본사)에 가지고 있으면서 각 지사별로는 지사에 해당된 로우(Row)를 가지고 있는 형태이다. 지사에 존재하는 데이터는 반드시 본사에 존재하게 된다.
즉 본사의 데이터는 지사데이터의 합이 되는 것이다.
각 지사에서 데이터 처리가 용이할 뿐만 아니라 전체 데이터에 대한 통합처리도 본사에 있는 통합 테이블을 이용하게 되므로 여러 테이블에 조인(JOIN)이 발생하지 않는 빠른 작업 수행이 가능해진다.
그림을 보면, 본사 데이터베이스에 있는 테이블에는 테이블의 전체 내용이 들어가고 각 지사 데이터베이스에 있는 테이블에는 지사별로 관계된 데이터만 들어가게 된다.
수평분할 분산과 마찬가지로 지사간에는 데이터의 중복이 발생하지 않으나 본사와 지사간에는 데이터의 중복이 항상 발생하게 되는 경우이다. 보통 전국에 있는 고객을 관리할 때 본사에는 전국고객에 대한 정보를 관리하고 지사에는 각 지사와 거래하는 고객정보를 관리한다.
본사의 데이터를 이용하여 통계, 이동 등을 관리하며 지사에 있는 데이터를 이용하여 지사별로 빠른 업무수행을 한다.
보통 지사에 데이터가 먼저 발생하고 본사에 데이터는 지사에 데이터를 이용하여 통합하여 발생된다.
실제 프로젝트에서 많이 사용하는 데이터베이스 분산기법에 해당한다.
각 지사별로 업무수행이 용이하고 본사에 있는 데이터를 이용하여 보고서를 출력하거나 통계를 산정하는 등 다양한 업무형태로 이용 가능하다. 다른 지역간의 데이터를 복제(Replication)하는데 많은 시간이 소요되고 데이터베이스와 서버에 부하(Load)가 발생하므로 보통 실시간(On-Line) 처리에 의해 복사하는 것보다는 야간에 배치 작업에 의해 수행되는 경우가 많이 있다. 또한 본사와 지사 양쪽 모두 데이터를 수정하여 전송하는 경우 데이터의 정합성을 일치시키는 것이 어렵기 때문에 가능하면 한쪽(지사)에서 데이터의 수정이 발생하여 본사로 복제(Replication)를 하도록 한다.
2>광역복제(Broadcast Replication)
통합된 테이블을 한군데(본사)에 가지고 있으면서 각 지사에도 본사와 동일한 데이터를 모두 가지고 있는 형태이다. 지사에 존재하는 데이터는 반드시 본사에 존재하게 된다. 모든 지사에 있는 데이터량과 본사에 있는 데이터량이 다 동일하다. 본사와 지사모두 동일한 정보를 가지고 있으므로 본사나 지사나 데이터처리에 특별한 제약을 받지는 않는다.
광역복제(Broadcast Replication) 역시 실제 프로젝트에서 많이 사용하는 데이터베이스 분산기법에 해당한다.
부분복제의 경우는 지사에서 데이터에 대한 입력, 수정, 삭제가 발생하여 본사에서 이용하는 방식이 많은 반면 광역복제(Broadcast Replication)의 경우에는 본사에서 데이터가 입력, 수정, 삭제가 되어 지사에서 이용하는 형태가 차이점이다. 부분복제와 마찬가지로 데이터를 복제(Replication)하는데 많은 시간이 소요되고 데이터베이스와 서버에 부하(Load)가 발생하므로 보통 실시간(On-Line) 처리에 의해 복사하는 것보다는 배치에 의해 복제가 되도록 한다.
라. 테이블 요약 분산
테이블 요약(Summarization) 분산은 지역간에 또는 서버 간에 데이터가 비슷하지만 서로 다른 유형으로 존재하는 경우이용된다.
요약의 방식에 따라,
동일한 테이블 구조를 가지고 있으면서 분산되어 있는 동일한 내용의 데이터를 이용하여 통합된 데이터를 산출하는 방식의 분석요약(Rollup Summarization)
분산되어 있는 다른 내용의 데이터를 이용하여 통합된 데이터를 산출하는 방식의 통합요약(Consolidation Summarization)이 있다.
1>분석요약(Rollup Replication)
분석요약(Rollup Replication)은 각 지사별로 존재하는 요약정보를 본사에 통합하여 다시 전체에 대해서 요약정보를 산출하는 분산방법이다.
예를 들어, 제품별 판매실적이라는 테이블이 존재한다고 가정하자.
각 지사에서는 취급제품이 동일하다.
지사별로 판매된 제품에 대해서 지사별로 판매실적이 관리된다.
지사1과 지사2에도 동일한 제품이 취급이 되므로 이를 본사에서 판매실적을 집계할 경우에는 통합된 판매실적을 관리할 수 있는 것이다.
각종 통계데이터를 산정할 경우에, 모든 지사의 데이터를 이용하여 처리하면 성능이 지연되고 각 지사 서버에 부하를 주기 때문에 업무에 장애가 발생할 수 있다. 통합 통계데이터에 대한 정보제공에 용이한 분산방법이다. 본사에 분석 요약된 테이블을 생성하고 데이터는 역시 일반 업무가 종료되는 야간에 수행하여 생성한다.
2>통합요약(Consolidation Replication)
통합요약(Consolidation Replication)은 각 지사별로 존재하는 다른 내용의 정보를 본사에 통합하여 다시 전체에 대해서 요약정보를 산출하는 분산방법이다.
테이블에 있는 모든 칼럼(Column)과 로우(Row)가 지사에도 동일하게 존재하지만 각 지사에는 타지사와 다른 요약정보를 가지고 있고 본사에는 각 지사의 요약정보를 데이터를 같은 위치에 두는 것으로 통합하여 전체에 대한 요약정보를 가지고 있는 것으로 표시된다.
본사에 통계데이터를 산정하는 유형은 분석요약과 비슷하나 통합요약은 단지 지사에서 산출한 요약정보를 한군데 취합하여 보여주는 형태이다.
분석요약은 지사에 있는 데이터를 이용하여 본사에서 통합하여 요약 데이터를 산정하였지만
통합요약에서는 지사에서 요약한 정보를 본사에서 취합하여 각 지사별로 데이터를 비교하기 위해 이용되는 것이다. 각종 통계데이터를 산정할 경우에, 모든 지사의 데이터를 조인하여 처리하면 성능이 지연되고 각 지사 서버에 부하(LOAD)를 주기 때문에 업무에 장애가 발생할 수 있다.
7) 분산 데이터베이스를 적용하여 성능이 향상된 사례
그림은
개인정보를 관리하는 데이터베이스가 인사 데이터베이스일 때,
분산이 안된 경우의 각 서버에 독립적으로 테이블이 있을 때,
트랜잭션과 복제분산을 통해 테이블의 정보가 양쪽에 있을 때,
트랜잭션 처리의 특성을 보여주는 그림이다.
단순한 개념도 이지만 위의 원리가 복잡한 업무처리에서 효과적으로 성능을 향상시킬 수 있음을 주목해야 한다.
데이터베이스 분산 설계는 다음과 같은 경우에 적용하면 효과적이다.
가. 성능이 중요한 사이트에 적용해야 한다.
나. 공통코드, 기준정보, 마스터 데이터 등에 대해 분산환경을 구성하면 성능이 좋아진다.
다. 실시간 동기화가 요구되지 않을 때 좋다.
거의 실시간(Near Real Time)의 업무적인 특징을 가지고 있을 때도 분산 환경을 구성할 수 있다
라. 특정 서버에 부하가 집중이 될 때 부하를 분산할 때도 좋다.
마. 백업 사이트(Disaster Recovery Site)를 구성할 때 간단하게 분산기능을 적용하여 구성할 수 있다.
성능 데이터 모델링이란 데이터베이스 성능향상을 목적으로 설계단계의 데이터베이스 모델링때부터 성능과 관련된 사항이 데이터 모델링에 반영될 수 있도록 하는 것이다.
인프라가 갖추어 지지 않은 환경에서 과연 빠른 속도로 이동할 수 있을까? 길이 굽이굽이 굽어져 있고 곳곳에 신호등이 있는 도로에서 아무리 성능이 좋은 차라고 할지라도 과연 그 길을 빠르게 지날 수 있을까? 데이터베이스에서 기본적으로 설계단계에서부터 성능을 고려하지 않고 설계를 하는 것은 빠르게 지나갈 수 없는 길을 지나가는 차에게 빨리 와달라고 요청하는 것과 다름이 없다. 데이터의 용량의 커질수록 기업의 의사결정의 속도가 빨라질수록 데이터를 처리하는 속도는 빠르게 처리되어야 할 필요성을 반증해 준다. 일반적으로 실무 프로젝트에서 보면 잘못된 테이블 디자인 위에서 개발된 애플리케이션의 성능이 저하되는 경우, 개발자가 구축한 SQL구문에 대해서만 책망을 하는 경우가 많이 있다. 물론 개발자가 SQL구문을 잘못 구성하여 성능이 저하되는 경우도 있지만 근본적으로 디자인이 잘못되어 SQL구문을 잘못 작성하도록 구성될 수밖에 없는 경우도 빈번하게 발생되고 있음을 기억해야 한다. 성능이 저하되는 경우는 크게 세가지로 이를 보완하면서 그 성능을 향상시킬 수 있다.
가. 데이터 모델 구조에 의한 성능 저하
나. 데이터가 대용량이 됨으로 인한 성능 저하
다. 인덱스 특성을 충분히 고려하지 않고 인덱스를 생성함 인한 성능 저하
일반적으로 성능이라고 하면 데이터조회의 성능을 의미하곤 한다.
그 이유는 데이터입력/수정/삭제는 일시적이고 빈번하지 않고 단건 처리가 많은 반면에,
데이터조회의 경우는 반복적이고 빈번하며 여러 건을 처리하는 경우가 많기 때문이다. 이러한 특징은 일반적인 트랜잭션의 성격이 조회의 패턴을 가지고 있다는 것이고 업무에 따라서는 입력/수정/삭제의 성능이 중요한 경우도 있다. 따라서 데이터 모델링을 할 때 어떤 작업 유형에 따라 성능 향상을 도모해야 하는지 목표를 분명하게 해야 정확한 성능향상 모델링을 할 수 있음을 기억해야 한다. 성능 데이터 모델링이란 데이터베이스 성능향상을 목적으로 설계단계의 데이터 모델링 때부터 정규화, 반정규화, 테이블통합, 테이블분할, 조인구조, PK, FK 등 여러 가지 성능과 관련된 사항이 데이터 모델링에 반영될 수 있도록 하는 것으로 정의할 수 있다.
2) 성능 데이터 모델링 수행시점
성능 향상을 위한 비용은 프로젝트 수행 중에 있어서 사전에 할수록 비용이 들지 않는다.
특히 분석/설계 단계에서 데이터 모델에 성능을 고려한 데이터 모델링을 수행할 경우 성능저하에 따른 재업무(Rework) 비용을 최소화 할 수 있는 기회를 가지게 된다.
분석/설계단계에서 데이터 모델은 대충하고, 성능이 저하되는 SQL문장을 튜닝하고, 부족한 하드웨어 용량(CPU, Memory 등)을 증설하는 등의 작업은 추가적인 비용을 소진하게 하는 원인이 된다.
특히 데이터의 증가가 빠를수록 성능저하에 따른 성능개선비용은 기하급수적으로 증가하게 된다.
3) 성능 데이터 모델링 고려사항
가. 데이터 모델링을 할 때 정규화를 정확하게 수행한다. 나. 데이터베이스 용량산정을 수행한다. 다. 데이터베이스에 발생되는 트랜잭션의 유형을 파악한다. 라. 용량과 트랜잭션의 유형에 따라 반정규화를 수행한다. 마. 이력모델의 조정, PK/FK조정, 슈퍼타입/서브타입 조정 등을 수행한다. 바. 성능관점에서 데이터 모델을 검증한다.
가. 데이터 모델링을 할 때 기본적으로 정규화를 완벽하게 수행해야 한다.
정규화된 모델이 데이터를 주요 관심사별로 분산시키는 효과가 있기 때문에 그 자체로 성능을 향상시키는 효과가 있다.
나. 테이블에 대한 용량산정을 수행하면 어떤 테이블에 데이터가 집중되는지 파악할 수 있다.
이 용량산정은 엔터티별로 데이터가 대용량인지를 구분하게 하기 때문에 테이블에 대한 성능고려를 엄격하게 적용해야 하는지 기준이 될 수 있다. 다. 데이터 모델에 발생되는 트랜잭션의 유형을 파악할 필요가 있다.
트랜잭션의 유형에 대한 파악은 CRUD 매트릭스를 보고 파악하는 것도 좋은 방법이 될 수 있고,
객체지향 모델링을 적용한다면 시퀀스 다이어그램을 보면 트랜잭션의 유형을 파악하기에 용이하다.
또한 화면에서 처리된 데이터의 종류들을 보면 이벤트(입력, 수정, 삭제, 조회)에 따라 테이블에 데이터가 어떻게 처리되는지를 유추할 수 있다. 트랜잭션의 유형을 파악하게 되면 SQL문장의 조인관계 테이블에서 데이터조회의 칼럼들을 파악할 수 있게 되어 그에 따라 성능을 고려한 데이터 모델을 설계할 수 있다. 라. 이렇게 파악된 용량산정과 트랜잭션의 유형데이터를 근거로 정확하게 테이블에 대해 반정규화를 적용하도록 한다. 반정규화는 테이블, 속성, 관계에 대해 포괄적인 반정규화의 방법을 적용해야 한다.
마. 대량 데이터가 처리되는 이력모델에 대해 성능고려를 하고 PK/FK의 순서가 인덱스 특성에 따라 성능에 영향을 미치는 영향도가 크기 때문에 반드시 PK/FK를 성능이 우수한 순서대로 칼럼의 순서를 조정해야 한다. 바. 성능에 대한 충분한 고려가 되었는지를 데이터 모델 검토를 통해 다시 한 번 확인하도록 한다. 데이터 모델 검토 시에 일반적인 데이터 모델 규칙만을 검증하지 말고 충분하게 성능이 고려되었는지를 체크리스트에 포함하여 검증하도록 한다.
2. 정규화와 성능
1) 정규화를 통한 성능 향상 전략
데이터 모델링 정규화의 궁극적인 목적은 반복적인 데이터를 분리하고,
각 데이터가 종속된 테이블에 적절하게(프로세스에 의해 데이터의 정합성이 지켜질 수 있어야 함) 배치되도록 하는 것이므로 이 함수의 종속성을 이용하여 정규화 작업이나 각 오브젝트에 속성을 배치하는 작업에 이용이 되는 것이다. 기본적으로 데이터는 속성간의 함수종속성에 근거하여 정규화되어야 한다.
정규화를 수행하면 항상 조회 성능이 저하되어 나타날까? 데이터처리의 성능이 무엇인지 정확히 구분하여 인식할 필요가 있다.
가. 조회 성능
나. 입력/수정/삭제 성능
두 가지 성능 모두 우수하면 좋겠지만 데이터 모델을 구성에 따라 두 성능이 반전되어 나타나는 경우가 많이 있다. 정규화를 수행한다는 것은 데이터를 결정하는 결정자에 의해 함수적 종속을 가지고 있는 일반속성을 의존자로 하여 입력/수정/삭제 이상을 제거하는 것이다.
데이터의 중복속성을 제거하고 결정자에 의해 동일한 의미의 일반속성이 하나의 테이블로 집약되므로 한 테이블의 데이터 용량이 최소화되는 효과가 있다.
따라서 정규화된 테이블은 데이터를 처리할 때 속도가 빨라질 수도 있고 느려질 수도 있는 특성이 있다.
그림을 보면 정규화 수행 모델은 데이터를 입력/수정/삭제할 때 일반적으로 반정규화된 테이블에 비해 처리 성능이 향상된다.
단 데이터를 조회할 때에는 처리 조건에 따라 조회 성능이 향상될 수도 있고 저하될 수도 있다.
따라서 일반적으로 정규화가 잘 되어 있으면 입력/수정/삭제의 성능이 향상되고, 반정규화를 많이 하면 조회의 성능이 향상된다고 인식될 수 있다.
그러나 데이터 모델링을 할 때 반정규화만이 조회 성능을 향상시킨다는 고정관념은 탈피되어야 한다.
정규화를 해서 성능이 저하되기는커녕 정규화를 해야만 성능이 향상되는 경우가 아주 많이 나타나기 때문이다.
2) 함수적 종속성(Functional Dependency)에 근거한 정규화 수행 필요
함수의 종속성(Functional Dependency)은 데이터들이 어떤 기준값에 의해 종속되는 현상을 지칭하는 것이다.
이 때 기준값을 결정자(Determinant)라 하고 종속되는 값을 종속자(Dependent)라고 한다.
그림에서 보면 사람이라는 엔터티는 주민등록번호, 이름, 출생지, 호주라는 속성이 존재한다.
여기에서 이름, 출생지, 호주라는 속성은 주민등록번호 속성에 종속된다.
만약 어떤 사람의 주민등록번호가 신고되면 그 사람의 이름, 출생지, 호주가 생성되어 단지 하나의 값만을 가지게 된다. 이를 기호로 표시하면, 다음과 같이 표현할 수 있다.
주민등록번호 -> (이름, 출생지, 호주)
즉 “주민등록번호가 이름, 출생지, 호주를 함수적으로 결정한다.” 라고 말할 수 있다.
3. 반정규화와 성능
1) 반정규화를 통한 성능향상 전략
가. 반정규화의 정의
여기에서 반정규화는 ‘반(Half)’의 의미가 아닌 '반대하다'의 의미이다.
비정규화는 아예 정규화를 수행하지 않은 모델을 지칭할 때 사용한다. 반정규화를 정의하면 정규화된 엔티티, 속성, 관계에 대해 시스템의 성능향상과 개발(Development)과 운영(Maintenance)의 단순화를 위해 중복, 통합, 분리 등을 수행하는 데이터 모델링의 기법을 의미한다.
반정규화는 성능을 향상시키기 위해 정규화된 데이터 모델에서 중복, 통합, 분리 등을 수행하는 모든 과정을 의미한다.
데이터 무결성이 깨질 수 있는 위험을 무릅쓰고 데이터를 중복하여 반정규화를 적용하는 경우는
첫째, 데이터를 조회할 때 디스크 I/O량이 많아서 성능이 저하되는 경우
둘째, 경로가 너무 멀어 조인으로 인한 성능이 저하되는 경우
셋째, 칼럼을 계산하여 읽을 때 성능이 저하되는 경우
정규화는 입력/수정/삭제에 대한 성능을 향상 및 조회 성능을 향상시키는 역할을 한다.
그러나 정규화만을 수행하면 엔터티의 갯수가 증가하고 관계가 많아져 일부 여러 개의 조인이 걸려야만 데이터를 가져오는 경우가 있다. 이러한 경우 업무적으로 조회에 대한 처리성능이 중요하다고 판단될 때 부분적으로 반정규화를 고려하게 되는 것이다.
또한 정규화의 함수적 종속관계는 위반하지 않지만 데이터의 중복성을 증가시켜야만 데이터조회의 성능을 향상시키는 경우가 있다. 이러한 경우 반정규화를 통해서 성능을 향상시킬 수 있게 되는 것이다.
프로젝트에서는 설계단계에서 반정규화를 적용하게 된다.
나. 반정규화의 적용방법
반정규화는 난이도 높은 데이터 모델링의 실무기술이다.
반정규화를 적용할 때는 기본적으로 데이터 무결성이 깨질 가능성이 많이 있기 때문에 반드시 데이터 무결성을 보장할 수 있는 방법을 고려한 이후에 반정규화를 적용하도록 해야 한다.
정규화와 반정규화 사이에는 Trade-Off 관계 즉, 마치 저울추가 양쪽에 존재하여 한쪽이 무거워지면 다른 쪽은 위로 올라가는 것처럼 정규화만을 강조하다 보면 성능의 이슈가 발생될 수 있고, 반정규화를 과도하게 적용하다 보면 데이터 무결성이 깨질 수 있는 위험이 증가하게 되는 것이다.
따라서 반정규화를 적용할 때에는 데이터 무결성이 중요함을 알고 데이터 무결성이 충분히 유지될 수 있도록 프로세스 처리에 있어서 안정성이 먼저 확인이 되어야 한다.
2) 반정규화의 기법
넓은 의미에서 반정규화를 고려할 때 성능을 향상시키기 위한 반정규화는 여러 가지가 나타날 수 있다.
가. 테이블 반정규화
나. 컬럼 반정규화
다. 관계 반정규화
테이블과 컬럼의 반정규화는 데이터 무결성에 영향을 미치게 되나,
관계의 반정규화는 데이터 무결성을 깨뜨릴 위험을 갖지 않고서도 데이터처리의 성능을 향상시킬 수 있는 반정규화의 기법이 된다.
데이터 모델 전체가 관계로 연결되어 있고 관계가 서로 먼 친척간에 조인관계가 빈번하게 되어 성능저하가 예상이 된다면 관계의 반정규화를 통해 성능향상을 도모할 필요가 있다.
반정규화를 적용할 때 기억해야 할 내용은 데이터를 입력, 수정, 삭제할 때는 성능이 떨어지는 점을 기억해야 하고 데이터의 무결성 유지에 주의를 해야 한다.
4. 대량 데이터에 따른 성능
1) 대량 데이터발생에 따른 테이블 분할 개요
아무리 설계가 잘되어 있는 데이터 모델이라고 하더라도 대량의 데이터가 하나의 테이블에 집약되어 있고,
하나의 하드웨어 공간에 저장되어 있으면 성능저하를 피하기가 힘들다.
이런 원리는 하나의 고속도로 차선을 넓게 시공하여 건설해도 교통량이 많게 되면 이 넓은 도로가 정체현상을 보이는 것과 비슷한 원리로 이해할 수 있다.
일의 처리되는 양이 한군데에 몰리는 현상은 어떤 업무에 있어서 중요한 업무에 해당되는 데이터가 특정 테이블에 있는 경우에 발생이 되는데 이런 경우 트랜잭션이 분산 처리될 수 있도록 테이블단위에서 분할의 방법을 적용할 필요가 있는 것이다.
가. 하나의 테이블에 데이터가 대량으로 집중되는 경우
나. 하나의 테이블에 여러 개의 칼럼이 존재하여 디스크에 많은 블록을 점유하는 경우
가. 대량의 데이터가 하나의 테이블에 존재하게 되면
인덱스를 생성할 때 인덱스의 크기(용량)가 커지게 되고
그렇게 되면 인덱스를 찾아가는 단계가 깊어지게 되어 조회의 성능에도 영향을 미치게 된다.
인덱스 크기가 커질 경우 조회의 성능에는 영향을 미치는 정도가 작지만,
데이터를 입력/수정/삭제하는 트랜잭션의 경우 인덱스의 특성상 일량이 증가하여 더 많이 성능의 저하를 유발하게 된다. 또한 데이터에 대한 범위 조회시 더 많은 I/O 유발할 수 있게 되어 성능저하를 유발할 수 있게 된다.
테이블에 많은 양의 데이터가 예상될 경우 파티셔닝을 적용하거나 PK에 의해 테이블을 분할하는 방법을 적용할 수 있다. Oracle의 경우 크게 LIST PARTITION(특정값 지정), RANGE PARTITION(범위), HASH PARTITION(해쉬적용), COMPOSITE PARTITION(범위와 해쉬가 복합) 등이 가능하다.
파니셔닝이란 ? 논리적으로는 하나의 테이블로 보이지만 물리적으로 여러 개의 테이블스페이스에 쪼개어 저장하는 구조
나. 칼럼이 많아지게 되면 물리적인 디스크에 여러 블록에 데이터가 저장되게 된다.
따라서 데이터를 처리할 때 여러 블록에서 데이터를 I/O해야 하는 즉 SQL문장의 성능이 저하될 수 특징을 가지게 된다. 물론, 테이블에 칼럼이 많아지는 현상은 정규화이론인 함수적 종속성에 근거하여 당연히 하나의 테이블에 설계할 수는 있다.
그러나 대량 데이터를 가진 테이블에서 불필요하게 많은 양의 I/O를 유발하여 성능이 저하되는 경우에는 이것을 기술적으로 분석하여 성능을 향상하는 방법으로 분할할 수 있다.
테이블의 1:1 분리로 해결
프로젝트를 수행할 때 때로는 하나의 테이블에 300개 이상의 칼럼을 가지고 있는 경우가 있다. 컴퓨터 화면 하나에는 볼 수가 없어서 스크롤을 하면서 하나의 테이블에 있는 칼럼을 구경해야 할 정도이다. 이렇게 많은 칼럼은 로우체이닝과 로우마이그레이션이 많아지게 되어 성능이 저하된다.
로우 길이가 너무 길어서 데이터 블록 하나에 데이터가 모두 저장되지 않고 두 개 이상의 블록에 걸쳐 하나의 로우가 저장되어 있는 형태가 로우체이닝(Row Chaining) 현상이다.
로우마이그레이션(Row Migration)은 데이터 블록에서 수정이 발생하면 수정된 데이터를 해당 데이터 블록에서 저장하지 못하고 다른 블록의 빈 공간을 찾아 저장하는 방식이다.
로우체이닝과 로우마이그레이션이 발생하여 많은 블록에 데이터가 저장되면 데이터베이스 메모리에서 디스크와 I/O(입력/출력)가 발생할 때 불필요하게 I/O가 많이 발생하여 성능이 저하된다.
2) 테이블에 대한 수평분할/수직분할의 절차
가. 데이터 모델링을 완성한다. 나. 데이터베이스 용량산정을 한다. 다. 대량 데이터가 처리되는 테이블에 대해서 트랜잭션 처리 패턴을 분석한다. 라. 칼럼 단위로 집중화된 처리가 발생하는지,
로우단위로 집중화된 처리가 발생되는지 분석하여 집중화된 단위로 테이블을 분리하는 것을 검토한다.
용량산정은 어느 테이블에 데이터의 양이 대용량이 되는지 분석하는 것이다.
특정 테이블의 용량이 대용량인 경우 칼럼의 수가 너무 많은 지 확인한다.
칼럼의 수가 많은 경우 트랜잭션의 특성에 따라 테이블을 1:1 형태로 분리할 수 있는지 검증하면 된다.
칼럼의 수가 적지만 데이터용량이 많아 성능저하가 예상이 되는 경우 테이블에 대해 파티셔닝 전략을 고려하도록 한다. 파티셔닝할 것인지 데이터가 발생되는 시간에 따라 파티셔닝을 할 것인지를 설명된 기준에 따라 적용하면 된다.