1. 관계형 데이터베이스 개요
1) 데이터 베이스
넓은 의미에서의 데이터베이스는 이러한 일상적인 정보들을 모아 놓은 것 자체를 의미한다.
그러나 일반적으로 데이터베이스라고 말할 때는 특정 기업이나 조직 또는 개인이 필요에 의해(ex: 부가가치가 발생하는) 데이터를 일정한 형태로 저장해 놓은 것을 의미한다.
예를 들어, 학교에서는 학생 관리를 목적으로 학생 개개인의 정보를 모아둘 것이고,
기업에서는 직원들을 관리하기 위해 직원들의 이름, 부서, 월급 등의 정보를 모아둘 것이다.
그리고 이러한 정보들을 관리하기 위해서 엑셀과 같은 소프트웨어를 이용하여 보기 좋게 정리하여 저장해 놓을 것이다.
그러나 관리 대상이 되는 데이터의 양이 점점 많아지고 같은 데이터를 여러 사람이 동시에 여러 용도로 사용하게 되면서 단순히 엑셀 같은 개인이 관리하는 소프트웨어 만으로는 한계에 부딪히게 된다.
또한 경우에 따라서는 개인의 사소한 부주의로 인해 기업의 사활이 걸린 중요한 데이터가 손상되거나 유실되는 상황이 발생할 수도 있다.
따라서 많은 사용자들은 보다 효율적인 데이터의 관리 뿐만 아니라 예기치 못한 사건으로 인한 데이터의 손상을 피하고, 필요시 필요한 데이터를 복구하기 위한 강력한 기능의 소프트웨어를 필요로 하게 되었고 이러한 기본적인 요구사항을 만족시켜주는 시스템을 DBMS(Database Management System)라고 한다.
2) SQL(Structured Query Language)
SQL(Structured Query Language)은 관계형 데이터베이스에서 데이터 정의, 데이터 조작, 데이터 제어를 하기 위해 사용하는 언어이다.
SQL의 문법이 영어 문법과 흡사하기 때문에 SQL 자체는 다른 개발 언어에 비해 기초 단계 학습은 쉬운 편이지만,
SQL이 시스템에 미치는 영향이 크므로 고급 SQL이나 SQL 튜닝의 중요성은 계속 커지고 있다.
SQL 문장은 단순 스크립트가 아니라 이름에도 포함되어 있듯이, 일반적인 개발 언어처럼 독립된 하나의 개발 언어이다. 하지만 일반적인 프로그래밍 언어와는 달리 SQL은 관계형 데이터베이스에 대한 전담 접속(다른 언어는 관계형 데이터베이스에 접속할 수 없다) 용도로 사용되며 집합 논리에 입각한 것이므로, SQL도 데이터를 집합으로써 취급한다. 예를 들어 ‘포지션이 미드필더(MF)인 선수의 정보를 검색한다’고 할 경우, 선수라는 큰 집합에서 포지션이 미드필더인 조건을 만족하는 요구 집합을 추출하는 조작이 된다.
이렇게 특정 데이터들의 집합에서 필요로 하는 데이터를 꺼내서 조회하고 새로운 데이터를 입력/수정/삭제하는 행위를 통해서 사용자는 데이터베이스와 대화하게 된다. 그리고 SQL은 이러한 대화를 가능하도록 매개 역할을 하는 것이다.
결과적으로 SQL 문장을 배우는 것이 곧 관계형 데이터베이스를 배우는 기본 단계라 할 수 있다.
SQL 문장의 종류는 다음과 같이 나누어진다.
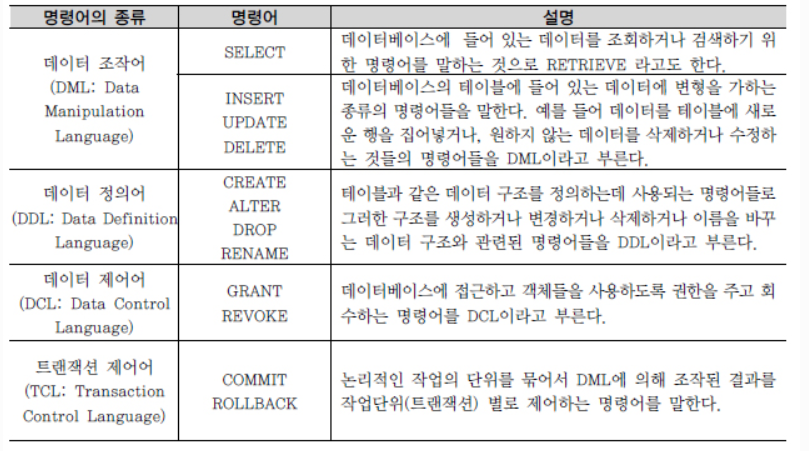
이들 SQL 명령어는 3가지 SAVEPOINT 그룹인 DDL, DML, DCL로 나눌 수 있는데, TCL의 경우 굳이 나눈다면 일부에서 DCL로 분류하기도 하지만, 다소 성격이 다르므로 별도의 4번째 그룹으로 분리할 것을 권고한다.
3) 테이블( TABLE )
데이터는 관계형 데이터베이스의 기본 단위인 테이블 형태로 저장된다.
모든 자료는 테이블에 등록이 되고, 우리는 테이블로부터 원하는 자료를 꺼내 올 수 있다.
축구 선수의 정보를 정리한다고 했을 때 아래의 그림과 같으면 한 눈에 알아보기가 어렵다.

그렇기 때문에 이를 더 직관적으로 확인할 수 있게 데이터를 테이블화시켜서 정리한다.
테이블에는 등록된 자료들이 있으며, 이 자료들은 삭제하지 않는 한 지속적으로 유지된다. 만약 우리가 자료를 입력하지 않는다면 테이블은 본래 만들어졌을 때부터 가지고 있던 속성을 그대로 유지하면서 존재하게 된다.

테이블에 대해서 좀 더 상세히 살펴보면 테이블(TABLE)은 데이터를 저장하는 객체(Object)로서 관계형 데이터베이스의 기본 단위이다.
관계형 데이터베이스에서는 모든 데이터를 칼럼과 행의 2차원 구조로 나타낸다.
세로 방향을 칼럼(Column), 가로 방향을 행(Row)이라고 하고, 칼럼과 행이 겹치는 하나의 공간을 필드(Field)라고 한다. 선수정보 테이블을 예로 들면 선수명과 포지션 등의 칼럼이 있고, 각 선수에 대한 데이터를 행으로 구성하여 저장한다.


2. DDL ( Data Definition Language : 데이터 정의어 )
1) 데이터 유형
데이터 유형은 데이터베이스의 테이블에 특정 자료를 입력할 때, 그 자료를 받아들일 공간을 자료의 유형별로 나누는 기준이라고 생각하면 된다.
따라서 선언한 유형이 아닌 다른 종류의 데이터가 들어오려고 하면 데이터베이스는 에러를 발생시킨다.
예를 들어 선수의 몸무게 정보를 모아놓은 공간에 ‘박지성’이라는 문자가 입력되었을 때, 숫자가 의미를 가지는 칼럼 정보에 문자가 입력되었으니 잘못된 데이터라고 판단할 수 있는 것이다.
또한 데이터 유형과 더불어 지정한 크기(SIZE)도 중요한 기능을 제공한다.

2) CREATE TABLE
가. CREATE TABLE
테이블은 일정한 형식에 의해서 생성된다.
테이블 생성을 위해서는 해당 테이블에 입력될 데이터를 정의하고,
정의한 데이터를 어떠한 데이터 유형으로 선언할 것인지를 결정해야 한다.
테이블에 존재하는 모든 데이터를 고유하게 식별할 수 있으면서 반드시 값이 존재하는 단일 칼럼이나 칼럼의 조합들(후보키) 중에 하나를 선정하여 기본키 칼럼으로 지정한다.
그리고 테이블과 테이블 간에 정의된 관계는 기본키(PRIMARY KEY)와 외부키(FOREIGN KEY)를 활용해서 설정하도록 한다.
테이블을 생성하는 구문 형식은 다음과 같다.
CREATE TABLE 테이블이름 ( 칼럼명1 DATATYPE [DEFAULT 형식], 칼럼명2 DATATYPE [DEFAULT 형식], 칼럼명2 DATATYPE [DEFAULT 형식] ) ;
테이블 생성 시에 주의해야 할 몇 가지 규칙
1. 테이블명은 객체를 의미할 수 있는 적절한 이름을 사용한다. 가능한 단수형을 권고한다.
2. 테이블 명은 다른 테이블의 이름과 중복되지 않아야 한다.
3. 한 테이블 내에서는 칼럼명이 중복되게 지정될 수 없다.
4. 테이블 이름을 지정하고 각 칼럼들은 괄호 "( )" 로 묶어 지정한다.
5. 각 칼럼들은 콤마 ","로 구분되고, 테이블 생성문의 끝은 항상 세미콜론 ";"으로 끝난다.
6. 칼럼에 대해서는 다른 테이블까지 고려하여 데이터베이스 내에서는 일관성 있게 사용하는 것이 좋다.(데이터 표준화 관점)
7. 칼럼 뒤에 데이터 유형은 꼭 지정되어야 한다.
8. 테이블명과 칼럼명은 반드시 문자로 시작해야 하고, 벤더별로 길이에 대한 한계가 있다.
9. 벤더에서 사전에 정의한 예약어(Reserved word)는 쓸 수 없다.
10. A-Z, a-z, 0 -9, _, $, # 문자만 허용된다.
아래 그림은 테이블 명명의 잘못 된 사례이다.

나. 제약조건( CONSTRAINT )
제약조건(CONSTRAINT)이란 데이터의 무결성을 유지하기 위한 데이터베이스의 보편적인 방법이다.
테이블을 생성할 때 제약조건을 반드시 기술할 필요는 없지만, 이후에 ALTER TABLE을 이용해서 추가, 수정하는 경우 데이터가 이미 입력된 경우라면 처리 과정이 쉽지 않으므로 초기 테이블 생성 시점부터 적합한 제약 조건에 대한 충분한 검토가 있어야 한다.
아래 그림은 제약조건의 종류이다.

3) ALTER TABLE
한 번 생성된 테이블은 특별히 사용자가 구조를 변경하기 전까지 생성 당시의 구조를 유지하게 된다.
처음의 테이블 구조를 그대로 유지하는 것이 최선이지만, 업무적인 요구 사항이나 시스템 운영상 테이블을 사용하는 도중에 변경해야 할 일들이 발생할 수도 있다.
이 경우 주로 칼럼을 추가/삭제하거나 제약조건을 추가/삭제하는 작업을 진행하게 된다.
가.ADD COLUMN
다음은 기존 테이블에 필요한 칼럼을 추가하는 명령이다.
주의할 것은 새롭게 추가된 칼럼은 테이블의 마지막 칼럼이 되며 칼럼의 위치를 지정할 수는 없다.
[예제] PLAYER 테이블에 ADDRESS(데이터 유형은 가변 문자로 자릿수 80자리로 설정한다.) 칼럼을 추가한다.
[답안] Oracle ALTER TABLE PLAYER ADD (ADDRESS VARCHAR2(80));
나.DROP COLUMN
DROP COLUMN은 테이블에서 필요 없는 칼럼을 삭제할 수 있으며, 데이터가 있거나 없거나 모두 삭제 가능하다.
한 번에 하나의 칼럼만 삭제 가능하며, 칼럼 삭제 후 최소 하나 이상의 칼럼이 테이블에 존재해야 한다.
주의할 부분은 한 번 삭제된 칼럼은 복구가 불가능하다. 다음은 테이블의 불필요한 칼럼을 삭제하는 명령이다.
[예제] 앞에서 PLAYER 테이블에 새롭게 추가한 ADDRESS 칼럼을 삭제한다.
[답안] Oracle ALTER TABLE PLAYER DROP COLUMN ADDRESS;
다.MODIFY COLUMN
테이블에 존재하는 칼럼에 대해서 ALTER TABLE 명령을 이용해 칼럼의 데이터 유형, 디폴트(DEFAULT) 값, NOT NULL 제약조건에 대한 변경을 포함할 수 있다. 다음은 테이블의 칼럼에 대한 정의를 변경하는 명령이다.
칼럼을 변경할 때는 몇 가지 사항을 고려해서 변경해야 한다.
1.해당 칼럼의 크기를 늘릴 수는 있지만 줄이지는 못한다. 이는 기존의 데이터가 훼손될 수 있기 때문이다.
2.해당 칼럼이 NULL 값만 가지고 있거나 테이블에 아무 행도 없으면 칼럼의 폭을 줄일 수 있다.
3.해당 칼럼이 NULL 값만을 가지고 있으면 데이터 유형을 변경할 수 있다.
4.해당 칼럼의 DEFAULT 값을 바꾸면 변경 작업 이후 발생하는 행 삽입에만 영향을 미치게 된다.
5.해당 칼럼에 NULL 값이 없을 경우에만 NOT NULL 제약조건을 추가할 수 있다.
[예제] TEAM 테이블의 ORIG_YYYY 칼럼의 데이터 유형을 CHAR(4)→VARCHAR2(8)으로 변경하고, 향후 입력되는 데이터의 DEFAULT 값으로 '20020129'을 적용하고, 모든 행의 ORIG_YYYY 칼럼에 NULL이 없으므로 제약조건을 NULL → NOT NULL로 변경한다.
[답안] Oracle ALTER TABLE TEAM_TEMP MODIFY (ORIG_YYYY VARCHAR2(8) DEFAULT '20020129' NOT NULL);
라.RENAME COLUMN
테이블을 생성하면서 만들어졌던 칼럼명을 어떤 이유로 불가피하게 변경해야 하는 경우에 유용하게 쓰일 수 있는 RENAME COLUMN 문구이다.
ALTER TABLE 테이블명 RENAME COLUMN 변경해야 할 칼럼명 TO 새로운 칼럼명;
ALTER TABLE PLAYER RENAME COLUMN PLAYER_ID TO TEMP_ID;
마.DROP CONSTRAINT.
테이블 생성 시 부여했던 제약조건을 삭제하는 명령어 형태는 다음과 같다.
ALTER TABLE 테이블명 DROP CONSTRAINT 제약조건명;
[예제] PLAYER 테이블의 외래키 제약조건을 삭제한다.
[답안] Oracle ALTER TABLE PLAYER DROP CONSTRAINT PLAYER_FK;
바. ADD CONSTRAINT
테이블 생성 시 제약조건을 적용하지 않았다면, 생성 이후에 필요에 의해서 제약조건을 추가할 수 있다. 다음은 특정 칼럼에 제약조건을 추가하는 명령어 형태이다.
.
ALTER TABLE 테이블명 ADD CONSTRAINT 제약조건명 제약조건 (칼럼명);
[예제] PLAYER 테이블에 TEAM 테이블과의 외래키 제약조건을 추가한다. 제약조건명은 PLAYER_FK로 하고, PLAYER 테이블의 TEAM_ID 칼럼이 TEAM 테이블의 TEAM_ID를 참조하는 조건이다.
[답안] ALTER TABLE PLAYER ADD CONSTRAINT PLAYER_FK FOREIGN KEY (TEAM_ID) REFERENCES TEAM(TEAM_ID); 테이블이 변경되었다.
[예제] PLAYER 테이블이 참조하는 TEAM 테이블을 제거해본다.
[답안] DROP TABLE TEAM; ERROR: 외래 키에 의해 참조되는 고유/기본 키가 테이블에 있다. ※ 테이블은 삭제되지 않음
[예제] PLAYER 테이블이 참조하는 TEAM 테이블의 데이터를 삭제해본다.
[답안] DELETE TEAM WHERE TEAM_ID = 'K10'; ERROR: 무결성 제약조건
(SCOTT.PLAYER_FK)이 위배되었다. 자식 레코드가 발견되었다. ※ 데이터는 삭제되지 않음
위와 같이 참조 제약조건을 추가하면 PLAYER 테이블의 TEAM_ID 칼럼이 TEAM 테이블의 TEAM_ID 칼럼을 참조하게 된다. 참조 무결성 옵션에 따라서 만약 TEAM 테이블이나 TEAM 테이블의 데이터를 삭제하려 할 경우 외부(PLAYER 테이블)에서 참조되고 있기 때문에 삭제가 불가능하게 제약을 할 수 있다.
즉, 외부키(FK)를 설정함으로써 실수에 의한 테이블 삭제나 필요한 데이터의 의도하지 않은 삭제와 같은 불상사를 방지하는 효과를 볼 수 있다.
4)RENAME TABLE
RENAME 명령어를 사용하여 테이블의 이름을 변경할 수 있다.
RENAME 변경전 테이블명 TO 변경후 테이블명;
[예제] RENAME 문장을 이용하여 TEAM 테이블명을 다른 이름으로 변경하고, 다시 TEAM 테이블로 변경한다.
[답안] RENAME TEAM TO TEAM_BACKUP;
RENAME TEAM_BACKUP TO TEAM;
5)DROP TABLE
테이블을 잘못 만들었거나 테이블이 더 이상 필요 없을 경우 해당 테이블을 삭제해야 한다. 다음은 불필요한 테이블을 삭제하는 명령이다.
DROP TABLE 테이블명 [CASCADE CONSTRAINT];
DROP 명령어를 사용하면 테이블의 모든 데이터 및 구조를 삭제한다. CASCADE CONSTRAINT 옵션은 해당 테이블과 관계가 있었던 참조되는 제약조건에 대해서도 삭제한다는 것을 의미한다. SQL Server에서는 CASCADE 옵션이 존재하지 않으며 테이블을 삭제하기 전에 참조하는 FOREIGN KEY 제약 조건 또는 참조하는 테이블을 먼저 삭제해야 한다.
6)TRUNCATE TABLE
TRUNCATE TABLE은 테이블 자체가 삭제되는 것이 아니고, 해당 테이블에 들어있던 모든 행들이 제거되고 저장 공간을 재사용 가능하도록 해제한다. 테이블 구조를 완전히 삭제하기 위해서는 DROP TABLE을 실행하면 된다.
TRUNCATE TABLE PLAYER;
DROP TABLE의 경우는 테이블 자체가 없어지기 때문에 테이블 구조를 확인할 수 없다.
반면 TRUNCATE TABLE의 경우는 테이블 구조는 그대로 유지한 체 데이터만 전부 삭제하는 기능이다.
TRUNCATE는 데이터 구조의 변경 없이 테이블의 데이터를 일괄 삭제하는 명령어로 DML로 분류할 수도 있지만 내부 처리 방식이나 Auto Commit 특성 등으로 인해 DDL로 분류하였다.
테이블에 있는 데이터를 삭제하는 명령어는 TRUNCATE TABLE 명령어 이외에도 다음 DML 절에서 살펴볼 DELETE 명령어가 있다.
그러나 DELETE와 TRUNCATE는 처리하는 방식 자체가 다르다.
테이블의 전체 데이터를 삭제하는 경우, 시스템 활용 측면에서는 DELETE TABLE 보다는 시스템 부하가 적은 TRUNCATE TABLE을 권고한다.
단, TRUNCATE TABLE의 경우 정상적인 복구가 불가능하므로 주의해야 한다.
2. DML ( Data Manipulation Language : 데이터 조작어 )
1) INSERT
DML은 만들어진 테이블에 관리하기를 원하는 자료들을 입력, 수정, 삭제, 조회하는 SQL이다.
테이블에 데이터를 입력하는 방법은 두 가지 유형이 있으며 한 번에 한 건만 입력된다.
INSERT INTO 테이블명 (COLUMN_LIST)VALUES (COLUMN_LIST에 넣을 VALUE_LIST);
INSERT INTO 테이블명 VALUES (전체 COLUMN에 넣을 VALUE_LIST);
첫 번째 유형은 테이블의 칼럼을 정의할 수 있는데, 이때 칼럼의 순서는 테이블의 칼럼 순서와 매치할 필요는 없으며, 정의하지 않은 칼럼은 Default로 NULL 값이 입력된다.
단, Primary Key나 Not NULL 로 지정된 칼럼은 NULL이 허용되지 않는다.
두 번째 유형은 모든 칼럼에 데이터를 입력하는 경우로 굳이 COLUMN_LIST를 언급하지 않아도 되지만, 칼럼의 순서대로 빠짐없이 데이터가 입력되어야 한다.
1.해당 칼럼명과 입력되어야 하는 값을 서로 1:1로 매핑해서 입력하면 된다.
2.해당 칼럼의 데이터 유형이 CHAR나 VARCHAR2 등 문자 유형일 경우 『 ' 』(SINGLE QUOTATION)로 입력할 값을 입력한다.
3.숫자일 경우 『 ' 』(SINGLE QUOTATION)을 붙이지 않아야 한다.
2) UPDATE
입력한 정보 중에 잘못 입력되거나 변경이 발생하여 정보를 수정해야 하는 경우가 발생할 수 있다.
UPDATE 다음에 수정되어야 할 칼럼이 존재하는 테이블명을 입력하고 SET 다음에 수정되어야 할 칼럼명과 해당 칼럼에 수정되는 값으로 수정이 이루어진다.
UPDATE 테이블명 SET 수정되어야 할 칼럼명 = 수정되기를 원하는 새로운 값;
[예제] 선수 테이블의 백넘버를 일괄적으로 99로 수정한다.
[정답] UPDATE PLAYER SET BACK_NO = 99;
3) DELETE
테이블의 정보가 필요 없게 되었을 경우 데이터 삭제를 수행한다.
DELETE FROM 다음에 삭제를 원하는 자료가 저장되어 있는 테이블명을 입력하고 실행한다.
이때 FROM 문구는 생략이 가능한 키워드이며, 뒤에서 배울 WHERE 절을 사용하지 않는다면 테이블의 전체 데이터가 삭제된다.
DELETE [FROM] 삭제를 원하는 정보가 들어있는 테이블명;
[예제] 선수 테이블의 데이터를 전부 삭제한다.
[정답] DELETE FROM PLAYER;
참고로 데이터베이스는 DDL 명령어와 DML 명령어를 처리하는 방식에 있어서 차이를 보인다. DDL(CREATE, ALTER, RENAME, DROP) 명령어인 경우에는 직접 데이터베이스의 테이블에 영향을 미치기 때문에 DDL 명령어를 입력하는 순간 명령어에 해당하는 작업이 즉시(AUTO COMMIT) 완료된다.
하지만 DML(INSERT, UPDATE, DELETE, SELECT) 명령어의 경우, 조작하려는 테이블을 메모리 버퍼에 올려놓고 작업을 하기 때문에 실시간으로 테이블에 영향을 미치는 것은 아니다. 따라서 버퍼에서 처리한 DML 명령어가 실제 테이블에 반영되기 위해서는 COMMIT 명령어를 입력하여 TRANSACTION을 종료해야 한다.
테이블의 전체 데이터를 삭제하는 경우, 시스템 활용 측면에서는 삭제된 데이터를 로그로 저장하는 DELETE TABLE 보다는 시스템 부하가 적은 TRUNCATE TABLE을 권고한다. 단, TRUNCATE TABLE의 경우 삭제된 데이터의 로그가 없으므로 ROLLBACK이 불가능하므로 주의해야 한다.
4) SELECT
사용자가 입력한 데이터는 언제라도 조회가 가능하다.
앞에서 입력한 자료들을 조회해보는 SQL 문은 다음과 같다.
[예제] 입력한 선수들의 정보를 모두 조회한다.
[답안] SELECT * FROM PLAYER;
해당 테이블의 모든 칼럼 정보를 보고 싶을 경우에는 와일드카드로 애스터리스크(*)를 사용하여 조회할 수 있다.
[예제] 조회하기를 원하는 칼럼명을 SELECT 다음에 콤마 구분자(,)로 구분하여 나열하고, FROM 다음에 해당 칼럼이 존재하는 테이블명을 입력하여 실행시킨다. 입력한 선수들의 데이터를 조회한다.
[답안] SELECT PLAYER_ID, PLAYER_NAME, TEAM_ID, POSITION, HEIGHT, WEIGHT, BACK_NO FROM PLAYER;
조회된 결과에 일종의 별명(ALIAS, ALIASES)을 부여해서 칼럼 레이블을 변경할 수 있다. 칼럼 별명(ALIAS)에 대한 사항을 정리하면 다음과 같다.
가. 칼럼명 바로 뒤에 온다.
나. 칼럼명과 ALIAS 사이에 AS, as 키워드를 사용할 수도 있다. (option)
다. 이중 인용부호(Double quotation)는 별명이 공백, 특수문자를 포함할 경우와 대소문자 구분이 필요할 경우 사용된다.
[예제] 칼럼 별명을 적용할 때 별명 중간에 공백이 들어가는 경우 『" " 』를 사용해야 한다.
[답안] SELECT PLAYER_NAME "선수 이름", POSITION "그라운드 포지션", HEIGHT "키", WEIGHT "몸무게" FROM PLAYER;
5) 산술연산자와 합성연산자
가. 산술연산자
산술 연산자는 NUMBER와 DATE 자료형에 대해 적용되며 일반적으로 수학에서의 4칙 연산과 동일하다.
그리고 우선순위를 위한 괄호 적용이 가능하다.
일반적으로 산술 연산을 사용하거나 특정 함수를 적용하게 되면 칼럼의 LABEL이 길어지게 되고, 기존의 칼럼에 대해 새로운 의미를 부여한 것이므로 적절한 ALIAS를 새롭게 부여하는 것이 좋다.
그리고 산술 연산자는 수학에서와 같이 (), *, /, +, - 의 우선순위를 가진다.

[예제] 선수들의 키에서 몸무게를 뺀 값을 알아본다.
[답안] SELECT PLAYER_NAME 이름, HEIGHT - WEIGHT "키-몸무게" FROM PLAYER;
나. 합성(CONCATENATION) 연산자
문자와 문자를 연결하는 합성(CONCATENATION) 연산자를 사용하면 별도의 프로그램 도움 없이도 SQL 문장만으로도 유용한 리포트를 출력할 수 있다.
합성(CONCATENATION) 연산자의 특징은 다음과 같다.
가. 문자와 문자를 연결하는 경우 2개의 수직 바(||)에 의해 이루어진다. (Oracle)
나. 문자와 문자를 연결하는 경우 + 표시에 의해 이루어진다. (SQL Server)
다. 두 벤더 모두 공통적으로 CONCAT (string1, string2) 함수를 사용할 수 있다.
라. 칼럼과 문자 또는 다른 칼럼과 연결시킨다.
마. 문자 표현식의 결과에 의해 새로운 칼럼을 생성한다.
[예제] 다음과 같은 선수들의 출력 형태를 만들어 본다.
출력 형태) 선수명 선수, 키 cm, 몸무게 kg 예) 박지성 선수, 176 cm, 70 kg
[답안] Oracle SELECT PLAYER_NAME || '선수,' || HEIGHT || 'cm,' || WEIGHT || 'kg' 체격정보 FROM PLAYER;
데이터 전문가 자격증 SQLD
2. SQL 기본 및 활용
1) SQL 기본
가. 관계형 데이터베이스 개요
나. DDL
다. DML
라. TCL
마. WHERE 절
바. 함수
사. GROUP BY, HAVING 절
아. ORDER BY 절
자. 조인
중
가. 관계형 데이터베이스 개요
나. DDL
다. DML
를 데이터 전문가 지식포털 DBGuide.net 을 바탕으로 정리, 요약했습니다.
데이터 전문가 지식포털 DBGuide.net
엔터티 속성 관계 식별자 데이터 모델의 이해 1. 엔터티의 개념 데이터 모델을 이해할 때 가장 명확하게 이해해야 하는 개념 중에 하나가 바로 엔터티(Entity)이다. 이것은 우리말로 실체, 객체라��
www.dbguide.net
해당 사이트에서 더욱 전문적인 데이터 관련 지식을 다루고 있으니, 꼭 한 번 확인하시면 좋을 것 같습니다!
'DB > 기본 개념' 카테고리의 다른 글
| [SQL 기본 및 활용] SQL 기본 - 3 (0) | 2020.09.02 |
|---|---|
| [SQL 기본 및 활용] SQL 기본 - 2 (0) | 2020.09.02 |
| [데이터 모델링의 이해] 데이터 모델과 성능 - 2 (0) | 2020.09.01 |
| [데이터 모델링의 이해] 데이터 모델과 성능 - 1 (0) | 2020.08.31 |
| [데이터 모델링의 이해] 데이터 모델링의 이해 - 2 (0) | 2020.08.31 |